












Query and debug
Find relevant data for your model and enhance the quality of your dataset.
Data insights
Visualize the data trends and distributions of your dataset health and annotation team performance.
Data versioning
Enhance your AI pipeline with advanced versioning and download functionalities.
Data annotation automation
Build high-quality models to automate the annotation process.
ML pipelines management at scale
Streamline complex ML pipelines.
Task automation
Create processes that automatically tune into events in your projects, such as status updates, without any additional prompt from you.
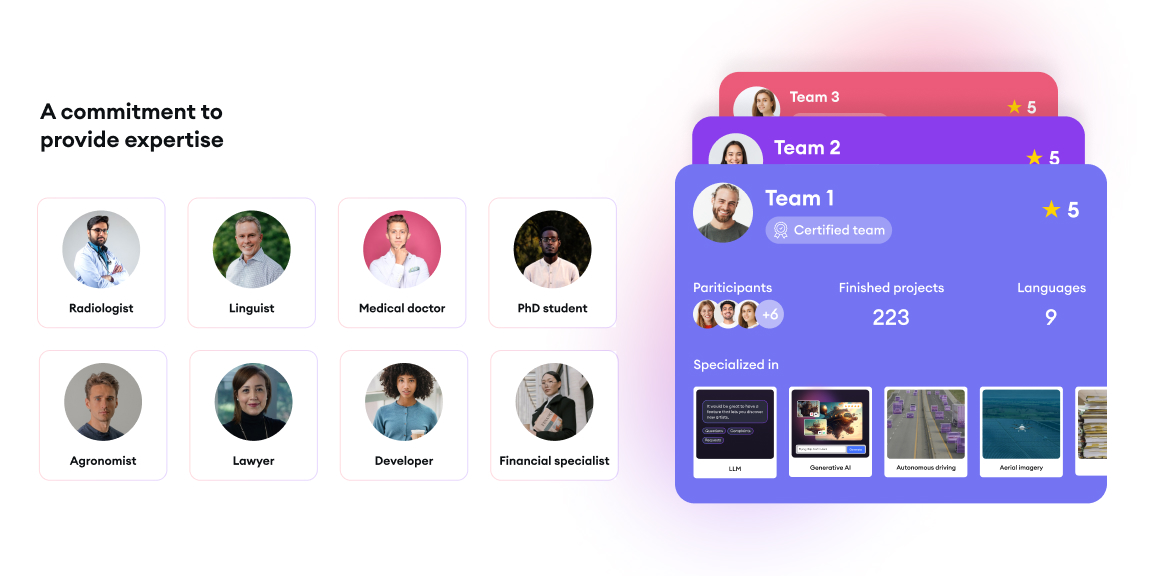
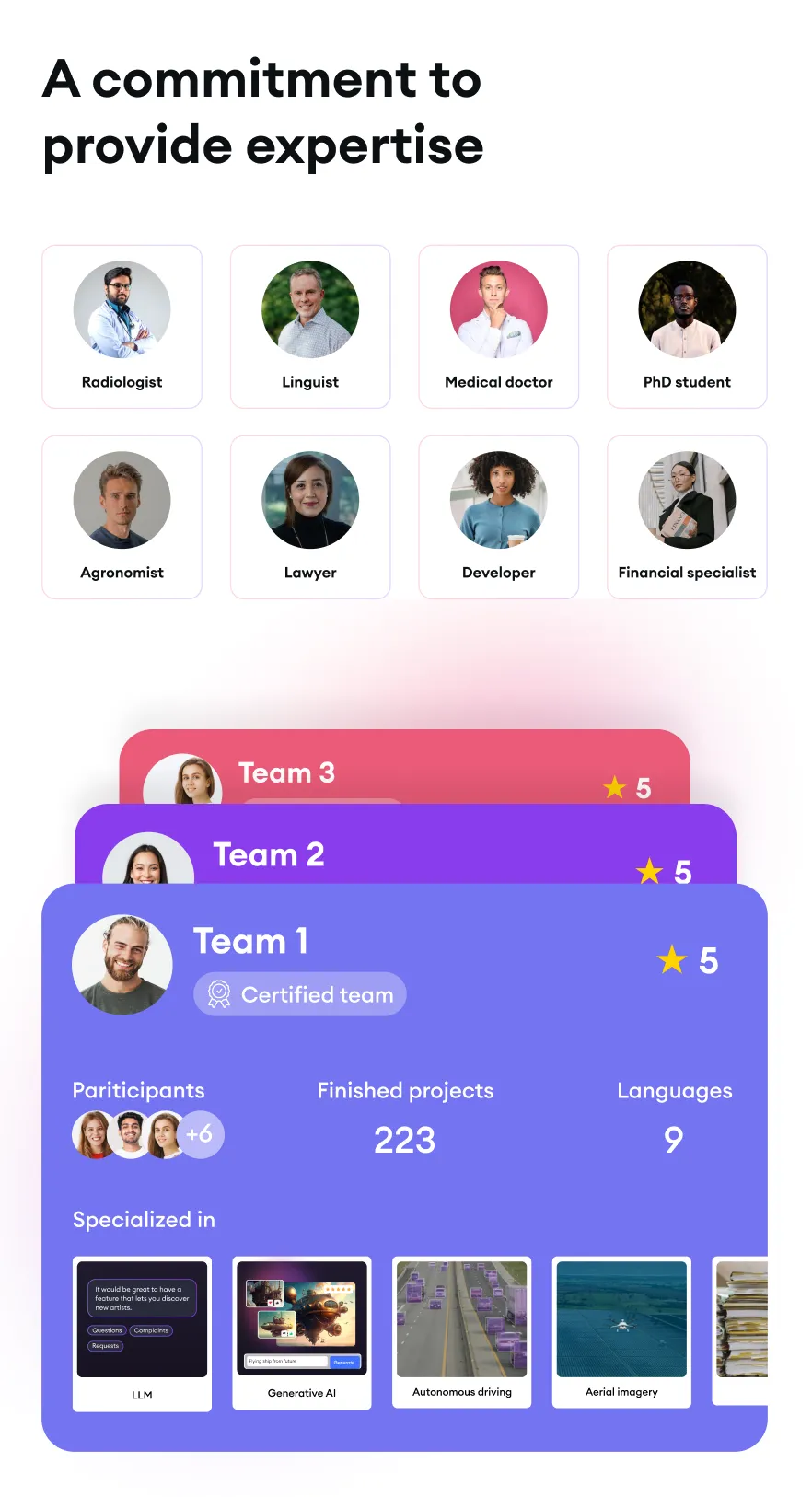
Scalability for projects of all sizes
Partner with SuperAnnotate's annotation service teams that provide quality and expertise to projects of all sizes across various industries.
Security measures to keep your data safe
SuperAnnotate complies with global security and privacy regulations and offers advanced solutions to keep your data safe.
Quality assurance infrastructure for high-quality data
No crowdsourcing! Our workforce is vetted, trained, and managed professionally.

Secure and compliant by design
Security Compliance

SOC 2 | TYPE 2
ISO 27001
HIPAA
SSO
GDPR
2FA
Data Integrations

AWS
Azure

GCP
They use SuperAnnotate. What’s your superpower?
96% model accuracy
“Definitely the best team annotators I’ve seen and the platform is easy to manage. The quality is really high and consistent.”
Robust and easy-to-use
“SuperAnnotate’s platform is incredibly robust and easy-to-use. Their Data Operations team is very thorough, proactive, easy to engage, and acts as a valuable extension of Motorola Solutions’ data operations.”
60% faster annotation cycle time
“We have complex projects, and SuperAnnotate has allowed us to cut over 60% off annotation cycle time, reducing it from over a week to a couple of days. Finding annotation teams was super easy, and because they are all trained on SuperAnnotate, they are able to deliver more accurate annotations much faster than before.”

12x more cost-efficient
“Two years ago, our team consisted of four people who were doing a thousand images over two months. Our data scientist is doing the same amount of work today in just one week. So, if I take 4x8, we get effectively nearly 32x faster.”

3x faster annotations
“The fact that SuperAnnnotate had a local dedicated team of professionals sped up the annotation performance and improved the quality of instrument annotations. That, combined with our local QA team, made a combination of 1+1 makes 3.”

Your AI deserves {SuperData}
Request Demo


Copyright © 2024 SuperAnnotate AI, Inc. All rights reserved.