


LLM judges became popular fast. They can review thousands of model outputs in minutes and seem like the perfect shortcut for evaluation at scale. But an LLM judge is just another model. It can reason, but it can also drift, miss context, or pick up bias from its data. The real challenge is learning how to build judges that teams can trust.
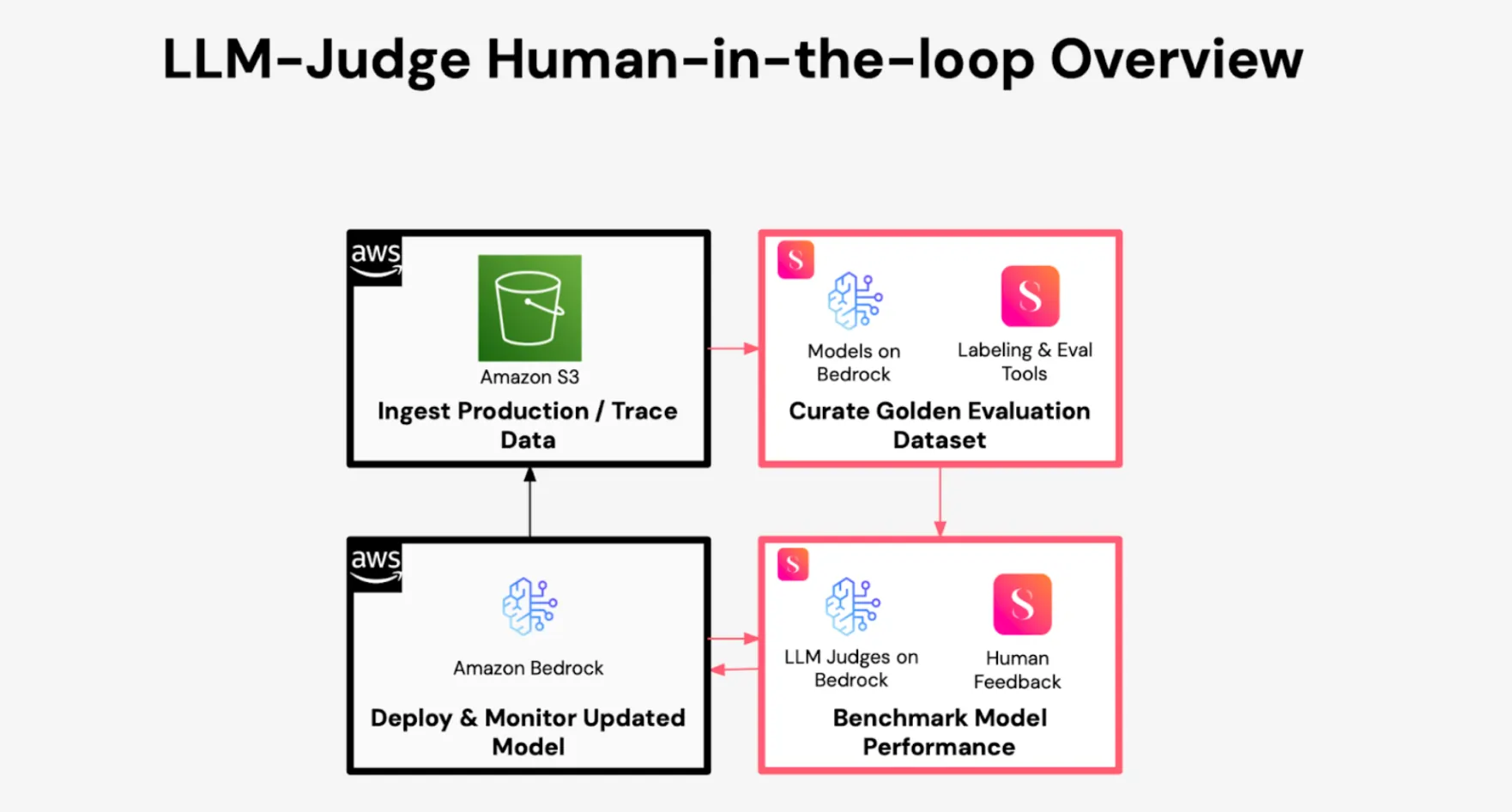
In our joint webinar with AWS, we shared what that looks like in practice. We covered how leading AI teams design judges with models hosted on AWS Bedrock and then improve their accuracy through human-in-the-loop annotation on SuperAnnotate.
Why Evaluation Decides Whether AI Scales
Almost everyone is building AI agents, yet very few make it into production. Deployment doesn’t usually fail because of missing frameworks. It fails because teams can’t prove what “good” looks like.
Without strong evaluation, a model might appear fine in a proof of concept but fail when real data arrives. Enterprises need a way to measure model quality with the same rigor used for software testing. That’s where LLM judges can help – if they’re built correctly.
The Data Behind a Reliable Judge
Evaluation always begins with data. Before designing a single metric, teams must have examples that capture their domain. The biggest gap most organizations face is unlabeled or loosely structured data.
SuperAnnotate’s platform helps solve this by turning raw inputs into labeled datasets that judges can learn from. AWS Bedrock then brings the compute and model orchestration to train and test those judges at scale. When the foundation is strong – clean data, clear examples, and defined metrics – evaluation becomes consistent across teams.
What Metrics Actually Matter
Generic metrics like BLEU or ROUGE often fail for generative tasks. They measure text similarity, not correctness or reasoning. A useful metric depends on the system being tested.
- Retrieval systems rely on context precision and recall.
- Question-answering systems need factual accuracy and relevance.
- Agent-based workflows care about whether the agent follows its goal and calls the right tools.
In regulated industries like healthcare, fairness, safety, and domain accuracy matter more than speed. The best setups combine shared evaluation metrics with custom domain ones that reflect what “quality” means for that business.

How to Build Judges You Can Trust
An LLM judge’s reliability depends on how it learns to rate responses.
- Teams define scales and examples for each metric so the judge understands what a “4” or “5” means.
- Human experts create the first labeled evaluations.
- The judge then compares its ratings against theirs until the agreement rate reaches a solid threshold.
- SuperAnnotate helps structure that loop by letting teams visualize human and judge disagreement, then retrain the judge through prompt or parameter updates.
- Over time, the system aligns with the team’s own standards instead of generic benchmarks.
Keeping Evaluation Continuous
Once a judge reaches production, the work continues. New data changes how models behave. A reliable pipeline samples outputs from production, sends them back for evaluation, and fine-tunes the judge to handle emerging edge cases. AWS infrastructure enables this loop to run securely at enterprise scale, while SuperAnnotate manages the workflow for data review, feedback, and reporting. The process forms a feedback engine – each round of evaluation sharpens both the model and the judge.
Final Thoughts
LLM judges make evaluation faster, but speed only matters when accuracy keeps up. The teams that succeed treat judges as systems that learn alongside their models, grounded in real data and guided by human oversight.
AWS and SuperAnnotate’s work shows that when evaluation becomes measurable, model deployment follows naturally.
Start building your own evaluation workflow with SuperAnnotate.
