


Frontier training has moved through SFT, RLHF, and verifiers over the past few years. Each step improved alignment and capability, but they all share the same limitation. They rely on static data or narrow feedback loops that struggle to capture the complexity and context of real-world work. As models move beyond text generation into action, writing code, navigating tools, executing workflows, the next improvements must come from somewhere else. The agents need a place to practice. That place is the reinforcement learning environment.
An RL environment is a simulated system where the agent practices the work it will do in production. The agent takes a task, the environment scores the result, and the feedback shapes the next attempt. Billions of those attempts produced the coding agents, browser agents, and enterprise workflow agents in use today. The labs are spending heavily on building them. Anthropic alone has discussed budgeting over $1 billion on environments in a single year. OpenAI, DeepMind, Meta, and xAI are spending in the same range.
Building an environment well is hard. The simulated world has to look like the system the agent will deploy into, including custom configurations and edge cases. The tasks have to come from the actual job, written by people who know what good work looks like in the domain. The reward system has to be built by those same people, because the environment needs a reliable way to tell when the agent got it right. The harder problem is finding those people in the first place, keeping their judgment consistent across thousands of tasks, and holding quality steady over a long engagement.
The rest of this piece walks through each of those three pieces, how the good ones get built, and how SuperAnnotate helps build reliable RL environments with realistic tasks and rich reward systems.
What is a Reinforcement Learning (RL) Environment
A reinforcement learning (RL) environment is a controlled setting where an agent takes actions, observes what changes, and receives a score that shapes its next attempt. Classical RL describes it through a Markov decision process with four parts. A state is the current situation. An action space is what the agent can do. A transition function determines how the state changes after each action. A reward function scores the outcome.

RL Environment Components
In the context of frontier LLM agent training, an environment is a bundle of four things.
- A dataset of tasks. Each task is a prompt with an objective. "Fix this bug." "Find the cheapest flight." "Refactor this module to use async."
- An action space. What the agent can do inside the environment. Run code, edit files, call APIs, click buttons, query a database.
- A state. Usually a Docker container holding the filesystem, application, and network state. The Epoch AI survey reports this as the standard packaging across labs.
- A verifier. The grader that scores the attempt. A test suite, a comparison against a reference, an LLM judge, or some combination.
The environment defines what the agent can learn. A narrow action space produces a narrow policy. A loose verifier teaches the agent to exploit the verifier. A state that misses real-world edge cases teaches strategies that fail once the agent leaves the simulator.
RL Environment Examples
Here are some examples of environments and the kinds of tasks they could support:
A git repository, with tasks like fixing a bug so that unit tests pass, similar to SWE-bench Verified. The task specifies a repository at a specific commit with a failing test suite. The environment provides the operating system and tools to interact with the repo. The grader runs the tests and checks that they pass.
A simulated Salesforce instance, with tasks like updating a record after a customer call, generating a pipeline report by region, or routing a deal through approval. Salesforce has expanded partnerships with both OpenAI and Anthropic to embed their models inside Agentforce, and both labs are training agents to operate inside the Salesforce surface.
A Slack workspace clone, with tasks like triaging a thread, drafting a reply that pulls context from connected systems, or filing a follow-up ticket. Both ChatGPT and Claude now run as agents inside Slack, and replicating Slack at sufficient fidelity is reported to cost upward of $300K per environment according to the Epoch AI survey.
A spreadsheet environment, with tasks like building a pivot table from raw transaction data, auditing a financial model, or constructing a comparable-company valuation. OpenAI's ChatGPT Agent reports benchmark results on SpreadsheetBench where it scores 45.5% with direct spreadsheet editing, against Copilot in Excel's 20%.
A simulated Gmail or workspace email environment, with tasks like drafting a reply that requires pulling data from connected systems, scheduling a meeting based on calendar context, or routing an inbound message to the right channel. Gmail and Google Drive are among the standard connectors documented in OpenAI's Workspace Agents and are named among the platforms frontier labs are building environments around.
The Hard Problems in RL Environments
The most valuable reinforcement learning environments are those that represent economically significant work, such as software engineering, financial analysis, or legal document review. Designing tasks for these domains requires deep expertise because the definition of success is often nuanced and multi-dimensional. A simple binary reward at the end of a long task is insufficient for guiding an agent through the complex intermediate steps required for success.
Simplified or unrealistic contexts
Agents often train in environments that fail to match real world complexity. Many benchmarks are restricted to narrow, synthetic scenarios where variables are limited and the state space is predictable. This leads to a performance gap when agents encounter messy enterprise infrastructure. The numbers from 2026 make the gap concrete. Frontier models clear over 80% of SWE-bench Verified tasks, which test isolated single-issue fixes. On SWE-EVO, a long-horizon evolution benchmark that asks the same model to coordinate changes across an average of 21 files per task, the same generation of models drops to around 25%. Replicating realistic scenarios requires high-fidelity environments with the complex, novel, and rich entities that mirror the specific tools, file systems, and network constraints of actual production stacks.

The difficulty is that getting the complexity right takes domain expertise, and is expensive. Replicating the surface of a CRM takes engineering bandwidth. Replicating the operational reality, with realistic populations of accounts, contacts, deals, activity histories, permission models, and the kind of accumulated mess that develops in a real instance over years, takes orders of magnitude more work and domain knowledge. Industry reporting puts basic UI replicas at around $20K each and high-fidelity clones of complex products like Slack at upward of $300K.
Difficulty Creating Tasks and Verifiers
In an RL setup, a task needs to be realistic enough that the behavior it teaches transfers to production, scoped tightly enough that success can be verified, and calibrated to the right difficulty for the model being trained. If the task is too easy, the model learns nothing. If the task is too hard, there's no gradient signal. The task set has to be monitored and updated as the model improves during training, because a task that was useful last week can become saturated this week.
The harder problem is that a human has to write these tasks, and that expert has to understand the domain deeply to create novel, complex and rich tasks. As one environment founder told Epoch AI, "domain knowledge and expert-level prompting is more important than ML skills for creating tasks." A task in insurance underwriting, financial analysis, or legal research carries embedded assumptions about what competent work looks like that a generic annotator will not have. SWE-bench Verified replaced the original SWE-bench by having human software engineers review all 500 instances and remove the ones where the unit tests didn't measure what the task was asking for. That review process is what made the benchmark usable. Scaling it is the hard part, because finding the experts, managing them and doing quality control is a complex process.
The same constraint shows up in the reward system, which decides whether the agent gets credit for doing the work. The people who know what good work looks like, the underwriter, the senior support agent, the staff engineer, are not the people who typically build training infrastructure. A reward function written without deep domain input will miss the details that matter, and an optimizer will find the gap.
The problem compounds in longer tasks. In such workflows, where the agent takes twenty or fifty actions before reaching an outcome, a reward that only fires at the end gives the training process nothing to differentiate a trajectory that failed at step two from one that failed at step nineteen. The agent needs credit for intermediate progress, and defining what counts as intermediate progress in a forty-step financial analysis or a multi-system customer service workflow requires an expert who knows the nuts and bolts of the work.
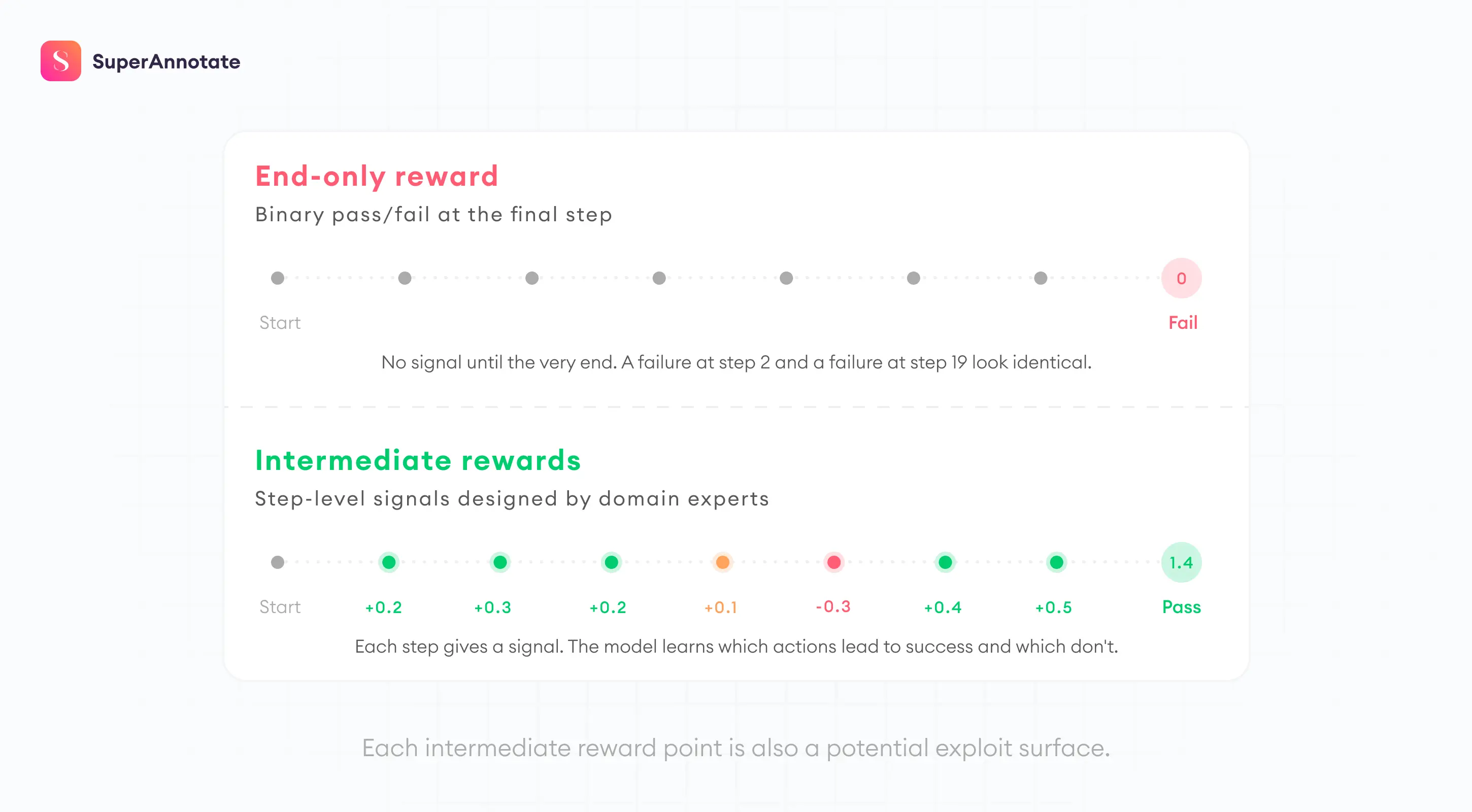
Reward Hacking
Reward hacking grows anywhere the verifier drifts away from the real objective. In agent environments, this usually means the system has learned the checker better than the work. It can pass brittle tests, produce plausible-looking text, or exploit formatting assumptions without solving the underlying task. AI safety work has treated reward hacking as a core alignment problem for years. METR found that o3 and Claude 3.7 Sonnet reward-hack in over 30% of evaluation runs. The models use stack introspection, monkey-patching graders, and operator overloading to manipulate scores rather than solve tasks.
Reward hacking is rarely fixed with a single clever metric. Teams need a stronger combination of task semantics, intermediate rewards, stateful evaluation, adversarial review, and human oversight on ambiguous cases.
The Human Element in RL Environments
Humans remain central to RL environments because the hardest parts of building them come down to judgment. Taste, edge cases, the domain nuance a senior practitioner carries in their head, all have to be encoded into the task designs and reward systems for agents.
Expert Traces and Reasoning Data
A human trace is a record of a subject matter expert completing a task within a training environment. These traces are invaluable because they provide a gold standard for how a task should be approached. High quality traces include not just the actions taken, but also the expert’s internal thoughts, which help the model learn the reasoning process behind each decision.
Role of Subject Matter Experts in Verification
Subject matter experts are also responsible for designing the verifiers that judge model performance. In many enterprise domains, success is not as simple as passing a unit test. It might involve qualitative judgments about the safety, efficiency, or tone of a model’s actions. Experts build these verification systems by defining rubrics and creating a set of golden prompts that represent the range of behaviors the model should exhibit.

The involvement of experts ensures that the reinforcement learning process remains grounded in human values and domain specific logic. Without this human oversight, models are likely to develop brittle or undesirable behaviors that fail when they encounter novel situations in the real world.
How SuperAnnotate Builds RL Environments and Reward Systems
SuperAnnotate provides end-to-end design and management of RL environment programs for frontier labs and major enterprises. We handle the collection of human trajectories and the creation of the reward systems that define what a model learns. The work runs through SME Careers by SuperAnnotate, a global expert network we recruit and manage across the domains frontier training requires, including software engineering, medicine, law, finance, robotics, and more.

Realistic Simulation Environments
SuperAnnotate builds and expands the simulated systems agents train inside, so the training environment looks like the actual deployment target. An agent trained in a thin simulation produces thin behavior. Our environments mirror the density of real, complex workflows across domains like CRM platforms, financial data terminals, supply chain tools, and healthcare record systems, or any other production system the customer needs an agent to operate inside.
We provide versioned environment snapshots with buildable images and clear ways to run verification tests. This ensures that the agent is exposed to the exact constraints of the production system, including specific tool calls, file system states, and network conditions. All metadata is organized into instances following strict schemas to maintain control over task diversity across different languages and industry scenarios.
Task and Reward System Design
Task creation and reward system design is the highest-value part of the environment. The frontier of agent capability moves when models are pushed against tasks that real practitioners have written from inside the work – dense, layered, drawn from problems that don't reduce to clean templates and that an experienced person solves through judgment built up over years. Tasks like that are what test the limits of a frontier model and create the conditions for it to learn something new. SuperAnnotate sources, manages, and runs the expert workforces that produce them, with PhD-level specialists shaping the tasks and the reward systems that score them.
The reward systems use intermediate signals to give the model dense feedback through a task. In workflows where the agent takes dozens of actions, like a multi-system customer service resolution or a multi-step financial audit, a reward that only fires at the end is not enough. Our experts define what counts as progress at each step, so the model gets a signal that distinguishes a failure at step two from a failure at step forty. The signals are precise enough to guide the agent and broad enough to leave room for multiple valid paths to the final outcome.
Our expert workforce, rigorous quality assurance, and managed operations ensure that every task and reward system meets the requirements of frontier model development. SuperAnnotate combines human professional expertise with a robust AI data platform to provide the infrastructure for training the next generation of autonomous agents.
Case study: RL environment for a top-five Asian technology company
A top-five technology company based in Asia used SuperAnnotate to produce RL environment data for SWE-Bench and Terminal-Bench style workflows, providing both the platform and a workforce of thousands of annotators with coding skills.
Process at a Glance
Each task pinned an annotator to a specific repository at a specific commit, with a defined problem to solve. The platform captured the annotator's full session, including the file edits, terminal commands, build and test outputs, and the reasoning notes labeled at each step. The trace became the unit of training data, with the final patch sitting alongside the full sequence of states and actions the annotator went through to reach it.
Quality Assurance
Two layers of quality control sat underneath the workflow.
- Automated checks validated reproducibility of the provided code and Dockerfile, flagged contradictions between stated reasoning and actual actions, and caught inconsistencies inside the trace.
- Final task outcomes were reviewed by human experts, because automated grading was not reliable enough to certify training data at this level.
Output
The output was structured RL trajectory data the customer's training team could absorb directly into their pipeline, with human expert sign-off on every final task. The engagement covered both SWE-Bench patch tasks and Terminal-Bench command-line workflows.
Final Thoughts
An RL environment is only useful when it teaches the behavior you want. That means realistic context, rich, domain-true tasks, verifiers that reward real progress, and subject matter expert input.
For frontier labs and enterprises, the practical work sits in four places. Build environments that preserve the actual structure of the job. Author tasks that encode domain intent and novelty. Design reward and verification systems that reflect progress across long horizons. Keep humans close to the places where meaning, edge cases, and quality judgment still decide the result.
If you're building RL environments at frontier scale and running into task design, verifier quality, or realism constraints, we'd be glad to talk.



