


AI systems have come a long way since the birth of ChatGPT in 2022, but getting them to work reliably in the real world is still far from automatic. In 2025, as agents start acting on their own, small mistakes can turn into big problems. A Taco Bell customer recently proved the point when he ordered 18000 waters through its AI drive-through, forcing the team to rethink the technology. One of the most efficient ways to avoid failures like this and worse is human-in-the-loop (HITL), a method that puts people directly into AI training and evaluation workflows.
“Creating high-quality AI data is extremely complex and time-consuming, but essential for training, improving and evaluating Agents, models and really any enterprise AI system. As a result, enterprise AI data needs the right expert touch, and the right tooling to streamline the development and management of modern AI applications. This is exactly what we are building at SuperAnnotate” - Vahan Petrosyan, Co-founder & CEO, SuperAnnotate
Language models are now being used to judge other models, agents are making decisions across multi-step tasks, and synthetic data is being generated at scale without enough checks. Without structured human feedback in the loop, quality becomes hard to measure, and progress becomes harder to trust.
In this article, we’ll discuss why human-in-the-loop matters, and what to look for in a platform that has human-in-the-loop integration.
What is Human-in-the-loop (HITL)?
Human-in-the-loop (HITL) is the practice of putting humans in AI model training. It’s how you build a feedback loop between your model and the domain experts who know what “good” looks like. Humans participate in model training and evaluation, offering their domain expertise to improve AI system performance.
HITL typically happens during:
- Data labeling: Humans annotate training examples, especially when the task is subjective, ambiguous, or domain-specific.
- Model evaluation: Humans assess outputs for quality, relevance, safety, or tone, often using structured rubrics.
- Feedback and correction: When a model fails or drifts, subject matter experts help diagnose and correct behavior, often feeding new examples back into training.
The result is a model that reflects the domain expertise, quality standards, and intent of the people building it.
Why Do You Need a Human-in-the-loop System?
In theory, large AI models learn patterns from data and generalize to new tasks. In practice, they learn what you show them, and generalize in ways you may not expect. That’s where HITL comes in: as the mechanism to observe and correct based on how a model actually performs in real cases.
Consider the case of a financial services firm building a document intelligence system. The base model performed well in sandboxed tests, but underperformed in production when faced with noisy scans, domain-specific language, and regional formatting differences. There was no model capacity issue, but there was a gap in data oversight and edge case coverage. The solution wasn’t architectural, it was operational. Finance experts were looped in to triage and annotate failures, improve labeling guidelines, and feed corrections back into training.
This pattern shows up repeatedly: in healthcare models misinterpreting rare symptoms, customer support assistants hallucinating on unfamiliar phrasing, or LLMs evaluating themselves without external checkpoints. HITL is what grounds these systems in the complexity and messiness of real data.
Cases Where AI Needs Human-in-the-Loop to Work
Over the past year, the most talked about AI topics – Agents, LLM-as-judges, synthetic data generation, have hit the same limits. The tools work, but they drift quickly without consistent human expertise and oversight.
AI Agents Keep Failing in Real Environments
Many teams working with AI agents have reported disappointing results. Agents often get stuck in loops, misread instructions, or take actions that completely miss the point in context. In fact, even the most capable AI agent, Google's Gemini 2.5 Pro, failed to complete real-world office tasks 70 percent of the time. Other models scored even lower.
While some say it’s the year of agents, Andrej Karpathy says it’s the decade. He referred to the next wave of software as partial autonomy apps built on LLMs, where humans continue to play a key role in oversight and control rather than handing over full autonomy.
“We have to keep the AI on the leash. A lot of people are getting way overexcited with AI agents,” said Karpathy.
Synthetic Data Alone Isn’t Reliable
AI models are falling apart as they ingest more AI-generated data. The push for synthetic data has unlocked a new scale, but it comes with tradeoffs. Models trained on synthetic or AI-generated data tend to reinforce their own biases, called model collapse. Over time, they learn from a narrower, self-confirming distribution that loses touch with the real world.
A 2024 study from Stanford showed that performance gains from synthetic data flattened quickly after the first few training rounds. In fact, overuse of synthetic samples sometimes led to performance regression.
The most optimal solution is mixing human and synthetic to balance the quality of AI training data, which would require domain experts to keep creating real content for AI training data. Keeping humans experts in the AI training and eval loop is the only way to not sacrifice quality.
LLM-as-judges Struggle Alone
LLM-as-a-judge – where one model rates or ranks the output of another – is a popular shortcut to scale evaluations. It’s an efficient technique, but it has to be done with caution. LLM judges sometimes misenterpret complex content, reward verbosity, and reinforce stylistic patterns instead of substance. In some cases, they assign high scores to completely false but confident-sounding answers.
A 2024 study on automated evaluation showed that LLM judges failed to match human judgments on academic writing, often misranking logically flawed arguments and missing reasoning gaps . These drift effects compound when models train on the scores of other models, without any human anchor.
While LLM-as-judges are highly effective for the first batch of evaluation, you can’t go alone with them. The evaluation cycle has to be controlled and overseen by humans. Because any real-world AI application includes tricky and niche edge cases where only a subject matter expert can make the right decision.
What a Modern HITL Workflow Looks Like
In enterprise environments, HITL is about operationalizing human feedback across the entire model lifecycle. That includes:
- Tight feedback loops between human reviewers and model outputs during training, evaluation, and post-deployment monitoring
- Real-time interfaces that allow product or QA teams to flag and annotate failure cases as they appear
- Analytics and versioning tools that track how human input shifts model behavior over time
A good HITL workflow gives the AI team visibility into where the model struggles, lets domain experts contribute corrections in context, and ensures updates are grounded in real data.
Human-in-the-loop Evaluation
Human-in-the-loop evaluation is mainly done in 2 phases - training and production.
HITL Evaluation in Training
HITL evaluation in the training phase helps track improvements, catch regressions, and confirm the model meets quality and safety standards before deployment. It involves four key steps:

1. Start with a curated evaluation dataset:
Use a large, general-purpose test set to confirm the model’s overall stability across many skills. Add a small, targeted prompt set when you only modified one feature or domain and want fast feedback on that specific slice.
2. Use LLM-as-a-judge evaluation for scale:
Run an automated assessment to quickly identify outputs that meet or fail key criteria. This setup allows fast iteration and highlights areas needing deeper review.
LLM-as-judges work best for binary questions – for instance, “Does the response reveal any PII information? Yes or No”. Filter failed or ambiguous outputs from the judge for manual review. This focuses expert attention where it adds the most value.
3. Maintain a fixed golden set (~200 prompts):
This curated set, reviewed by domain experts, acts as a gatekeeper for quality. New model versions must pass this set before moving to production. Curated sets allow for testing many use cases with a small prompt set, catching improvements or regressions easily while keeping the cost of human expert evaluations in check.
4. Compare new versions consistently:
Re-run the same evaluation tests after each update to detect regressions and track improvements. Think of this as designing unit testing for your model: it must be repeatable, auditable, and transparent.
HITL Evaluation in Production
HITL eval in production helps monitor the model after deployment, catch issues that aren’t visible in lab settings and track new model behaviours and use cases. It runs in 3 main phases:

1. Run automated LLM-based scoring:
Evaluate all outputs with LLM-as-a-judge across key quality dimensions (e.g., relevance, safety, and custom binary metrics). This allows you to monitor performance continuously without needing human review for every output. Filter failures and escalate to experts in the same way as in the training phase.
2. Sample strategically to control costs:
Continuous full-coverage evaluation quickly becomes prohibitively expensive at scale. Instead, evaluate a manageable baseline—typically 1–5% of random production outputs. Supplement this by actively sampling outputs flagged negatively by users ("thumbs-down") and known error-prone categories. Finally, outputs that score poorly with LLM-as-judge or show judge disagreement, or where judges are positive but a user is negative, should be sent to expert evaluation. This ensures ambiguous or novel failure modes are caught, as well as continued examination of the judge’s performance. This combined approach balances cost with coverage, providing meaningful insights at a reasonable budget.
3. Feed evaluation results back into training:
Use failed or edge-case examples to retrain, update, or expand the Persistent Prompt set. This closes the loop, keeps the model improving post-deployment, and handles data drift.
What a Human-in-the-loop Platform Really Means
At this point, a fair question is:
"If human-in-the-loop is so important, how do you operationalize it? What does a 'human-in-the-loop platform' actually do?"
In short: a human-in-the-loop platform gives teams the infrastructure to manage structured human feedback at scale – as a repeatable, versioned, quality-controlled part of the AI lifecycle.
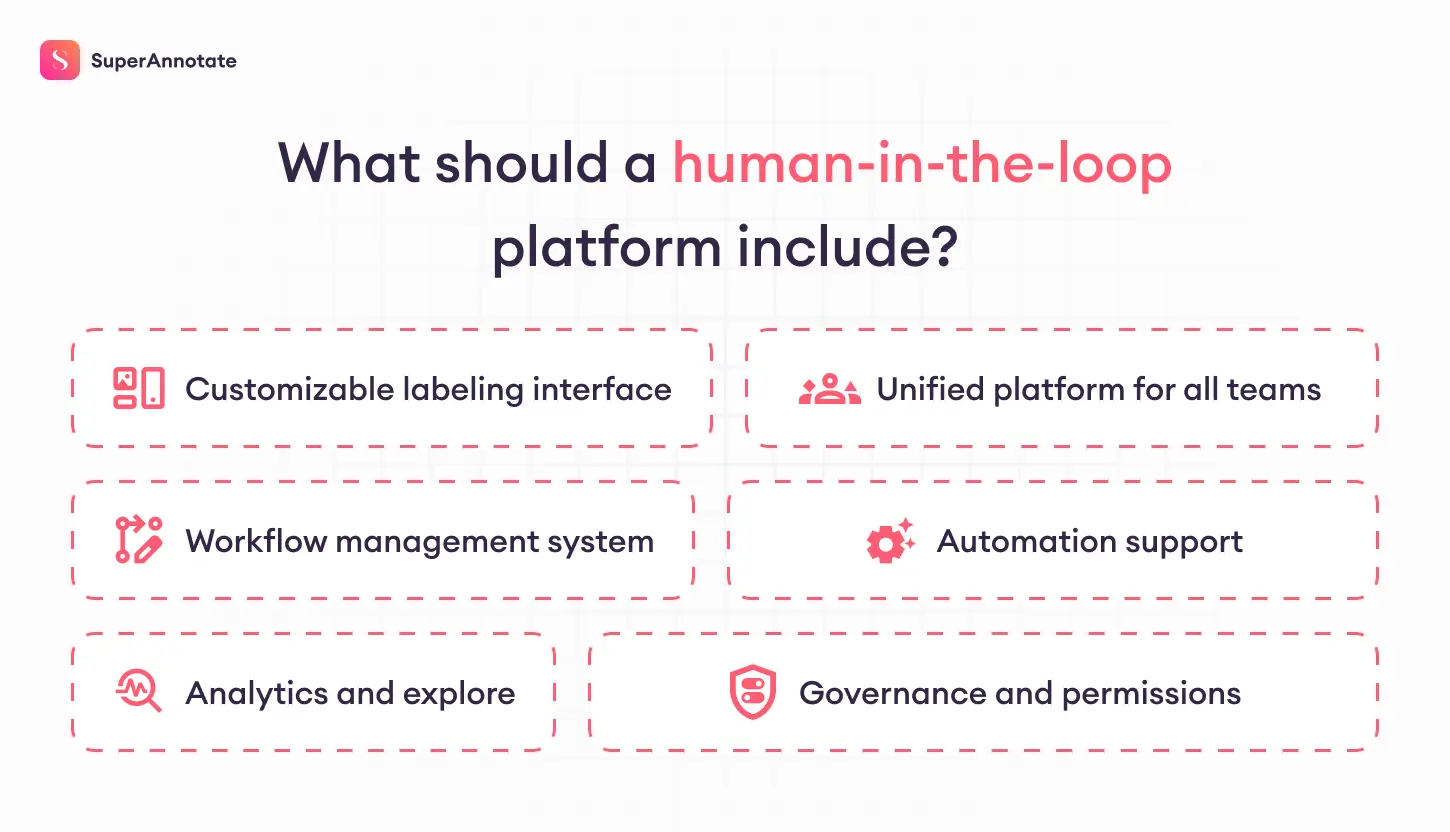
Here’s what that includes, in practical terms:
- Customizable labeling interfaces for any use case and any modality (text, image, audio, etc.).
- Unified platform where your internal team, outside vendors, and contractors work inside the same system with clear roles and tasks.
- Workflow management system with flexibility to manage multiple roles and teams and route tasks to the right people (internal teams, contractors, domain experts).
- Automation support that lets you run consensus checks, orchestrate automated scoring, and assign edge cases to humans based on predefined logic.
- Analytics and explore dashboards that let you track progress, review quality, and understand where performance is strong or weak.
- Governance and permissions to keep enterprise compliance and auditability in place.
SuperAnnotate covers all of this by default. You can build full evaluation workflows with human reviewers, LLM scoring, or combined. The platform gives you control over the setup, helps you manage the flow of tasks, and tracks performance over time – all in one place.
FInal Thoughts
There’s a lot of hype around AI systems doing more on their own, but the best results still come when people stay involved. Human-in-the-loop is a way to build systems that work reliably and accurately. You need structure, real-world checks, and a steady feedback loop between humans and models. The stronger that loop is, the better the system gets over time.
AI teams chasing scale without human oversight usually hit the same wall. The ones that invest in tight human-in-the-loop setups – with clear workflows, real evaluation, and trusted data – are the ones shipping systems that hold up in the long run.

Common Questions
This FAQ section highlights the key points about human-in-the-loop (HITL).


