


As companies rely more heavily on LLMs for business-critical tasks, measuring their success has become a significant concern. Most top tier models look great on paper because they pass academic tests with high scores. But when you put those same models into a real company environment with messy data and old documents, they often fall apart.
This happens because those standard tests don't actually check for the skills people need at work. The Databricks OfficeQA benchmark was built to fix this. It focuses on grounded reasoning – a way of saying an AI needs to find, read, and understand specific information from a company’s private documents.
To build OfficeQA, Databricks worked with SuperAnnotate to create a high-quality dataset based on roughly 90,000 pages of U.S. Treasury Bulletins. Expert reviewers wrote challenging, document-dependent questions and verified the answers against the source material. The results show that even the strongest models struggle with these tasks, especially on harder questions. OfficeQA provides a more realistic way to evaluate how well AI systems handle business-relevant reasoning.
Why Standard Benchmarks Fail Businesses
The way AI is currently tested has not kept up with how fast the technology is moving. Most existing benchmarks were made for researchers rather than businesses. GDPVal, ARC-AGI-2, and Humanity’s Last Exam (HLE) don’t help with real, business-relevant tasks.
In business applications, even a single digit error on a product or invoice number can have catastrophic downstream results. Being off by 5% when forecasting revenue can lead to dramatically incorrect business decisions. Databricks tested the current top models that are performing extremely well on standard benchmarks – and found that they succeeded on less than 40% of challenging business tasks.
The Need for Grounded Reasoning
Databricks realized that businesses need a different way to measure AI. They turned to SuperAnnotate to build a benchmark with questions that require grounded reasoning. Grounded reasoning forces an AI system to stay tied to facts and real documents, making the OfficeQA benchmark a real indicator of how well an AI system can handle business-relevant reasoning.
These documents are often messy corporate files in unfamiliar formats. For OfficeQA, this work was carried out through a trusted data partner. Building and validating the benchmark dataset and ground truth required subject matter experts to reason through documents the way people do at work. SuperAnnotate recruited and onboarded vetted experts who could read complex source documents and design questions that require step-by-step reasoning grounded in the underlying data. Instead of performing simple annotation tasks, these experts acted as judges, constructing logic problems that reveal whether a model can truly support business-critical workflows.
Building the OfficeQA Benchmark
To make a test that feels like real work, Databricks chose a dataset that is hard for machines to read, containing long tables, footnotes, historical revisions and inconsistencies that require careful interpretation. They selected around 90,000 U.S. Treasury Bulletins from 1939 all the way to 2025.
The Challenge of "Messy" Corporate Data
These documents are difficult for AI systems because they vary widely in format and structure. Some are old scans that are blurry or contain errors from the digitization process. Others are newer digital files with dense layouts and complex tables. Much of the information is embedded in large tables, where a single value depends on understanding how rows, columns, and headers relate to each other.
The documents also change over time. Financial reports are often revised or reissued, which means multiple versions of the same data can exist. An AI needs to keep searching past the first plausible answer and use the most current and authoritative source. In some cases, information is also presented in charts or figures, which requires visual understanding rather than simple text extraction.
How SuperAnnotate Helped
Creating this benchmark required human experts with nuanced attention to detail and deep reasoning skills. Databricks needed questions that would mirror the hardest parts of a real-world analysis, critical thinking, and problem solving, which needs a level of reasoning that goes far beyond simple fact finding.
“SuperAnnotate's deep understanding of our research requirements, combined with their ability to recruit highly qualified human reviewers and deliver thoughtful, framework-driven solutions, has super-powered our ability to efficiently build high-quality benchmarks, accelerating our research team's work on solving the most impactful customer problems.”
- Krista Opsahl-Ong, Research Engineer, Databricks
To make this happen, SuperAnnotate designed and operated a structured annotation and validation workflow, supported by a team of vetted domain experts through our fully managed workforce service SME Careers. The focus was on writing questions with one clear answer, grounding every answer in the source documents, and checking the work through a second pass by another expert. We onboarded experts across coding, math, and data analysis domains.
Data Workflow in the OfficeQA Project
OfficeQA consists of 246 questions split into two difficulty levels, easy and hard, based on how existing AI systems perform. Across a representative sample, human solvers required an average of 50 minutes per question, reflecting the amount of document navigation and reasoning involved.
The dataset was built through a structured, multi-step workflow.
- Source review and selection
Experts reviewed the documents to identify sections that were difficult to interpret, such as complex tables, tricky footnotes, or data spread across multiple pages. - Question creation
Using these sources, experts wrote questions that required multi-step reasoning. - Model filtering
Questions were tested against top-performing AI models. Any question that a model could answer without reading the documents was removed. - Expert review and validation
Each item went through a two-person review process. One expert created the question and answer, and a second expert verified the source material, reasoning, and final result.
Throughout the process, source documents, reasoning steps, and final answers were kept separate. This made it possible to trace errors and helped Databricks use OfficeQA as a practical benchmark for document-based reasoning.
What the Results Tell Us
The results from OfficeQA are a wake up call for the industry. Without access to the Treasury documents, they answer ~2% of questions correctly. When provided with a corpus of PDF documents, AI systems perform at <45% accuracy across all questions and <25% on a subset of the hardest questions.
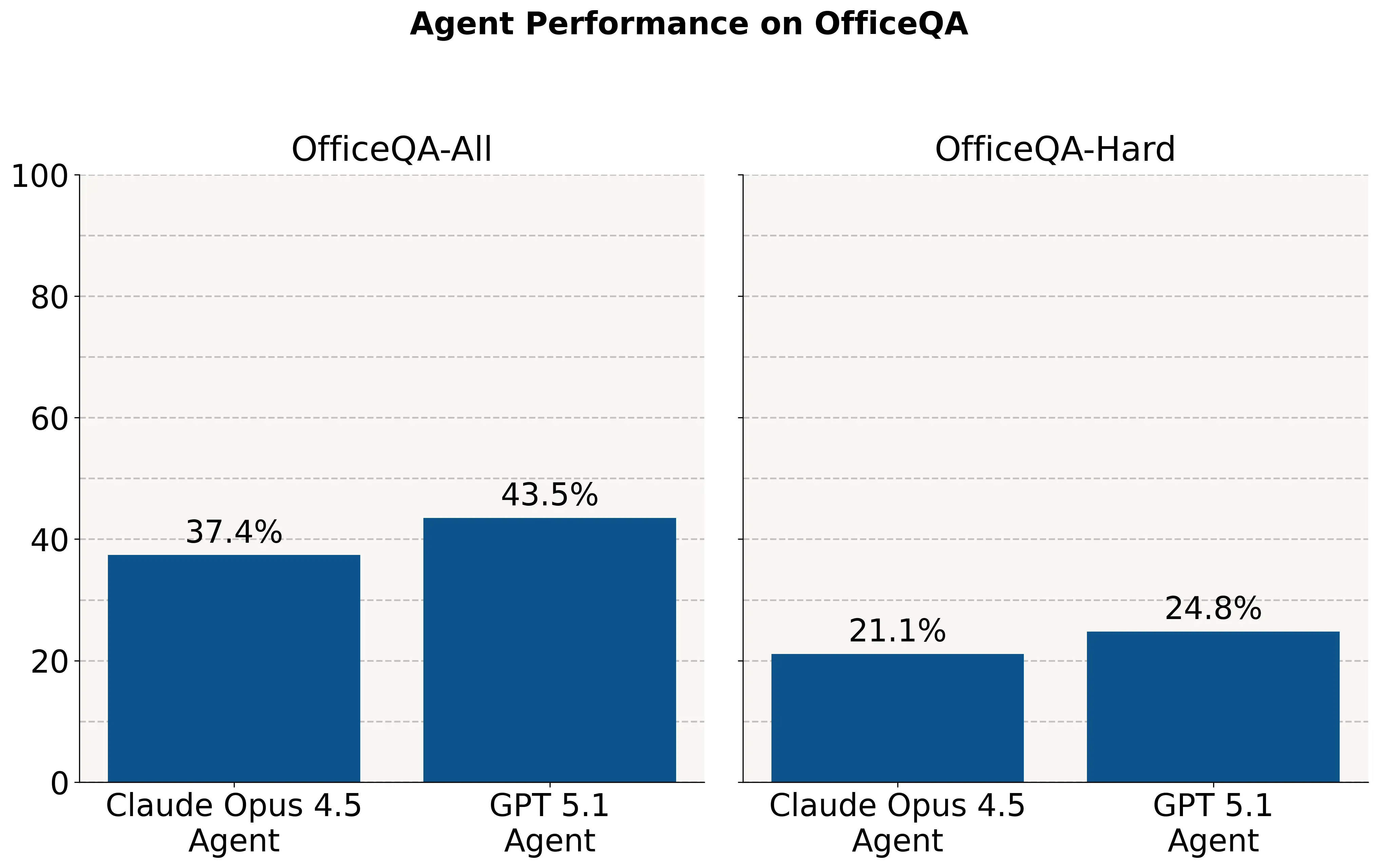
This performance gap highlights three critical truths:
- Top models aren't business-ready: Elite models that pass bars exams often struggle on economically important tasks and navigating messy, intersecting data.
- Standard benchmarks are insufficient: Research-focused tests are too shallow to evaluate if a model is ready for the precision required in corporate environments.
- Human expertise is the only true measure: Building a test this rigorous requires the nuanced knowledge of experts with years of field experience to create logic puzzles that machines cannot simply "guess" their way through.
The Future of Business AI
This partnership shows that humans are still a big part of the process. Instead of doing simple tasks, people are now acting as expert judges. They are building ground truth datasets based on complex reasoning tasks that verify if a machine is smart enough to handle a company's most important data. As more companies move their AI projects into the real world, this style of rigorous testing will become the standard. High quality data is the only way to build an AI that businesses can actually trust.


