


Fast-growing AI companies face a challenging balancing act: moving quickly while still maintaining high levels of accuracy. Doing both at scale is hard – especially when customer trust depends on getting every recommendation right.
Wizard, an AI-powered shopping agent, helps people discover products by analyzing reviews, editorials, and user conversations, to deliver personalized recommendations. From first search to checkout, the experience depends on relevance and precision.
As Wizard’s query volume grew, so did the number of recommendations that needed validation. Their fully manual evaluation process ensured strong quality, but it slowed iteration cycles and increased operational costs.
To scale without compromising precision, Wizard needed a new approach to evaluation.
In collaboration with SuperAnnotate and NVIDIA, Wizard built a hybrid human-LLM evaluation system powered by an NVIDIA Nemotron LLM Judge.
The results:
- Exceptional Quality: 96% residual accuracy
- Faster Cycle Time: 75% reduction in human annotation time
- Increased Throughput: 400% faster iteration cycles
- Strong Alignment: 91% alignment rate with human experts
This blog walks through the challenge, hybrid evaluation architecture, and measurable impact of this collaboration.
The Challenge: Manual Evaluation Was Accurate But Not Scalable
Customer trust depends on providing highly relevant recommendations, making it critical to ensure that the AI systems behind the Wizard shopping agent act as expected. Every recommendation must:
- Match user intent
- Meet quality standards
- Provide a balanced, diverse selection
To guarantee the highest quality of these recommendations, Wizard implemented a human evaluation pipeline with SuperAnnotate - the foundation of their quality control process.
A team of 18 evaluators reviewed every query across three dimensions:
1. Relevance - Does the recommendation reflect the user’s stated needs and preferences?
2. Quality - Does the product meet credibility markers (ratings, reviews, reputation)?
3. Diversity - Does the user receive a varied and well-balanced selection?
The workflow included:
- 100% human evaluation of live queries
- One full round of annotation and quality checks
- ~4 minutes average handling time per end-to-end review
This process delivered high precision. However, as volume scaled, costs and cycle times increased proportionally. To sustain growth, Wizard needed an evaluation framework that preserved human-level rigor while reducing operational load.
Key Technical Objectives
Wizard set three goals:
- Accelerate evaluation cycles without compromising quality
- Reduce dependency on fully manual human review
- Maintain strong alignment between automated outputs and human judgment
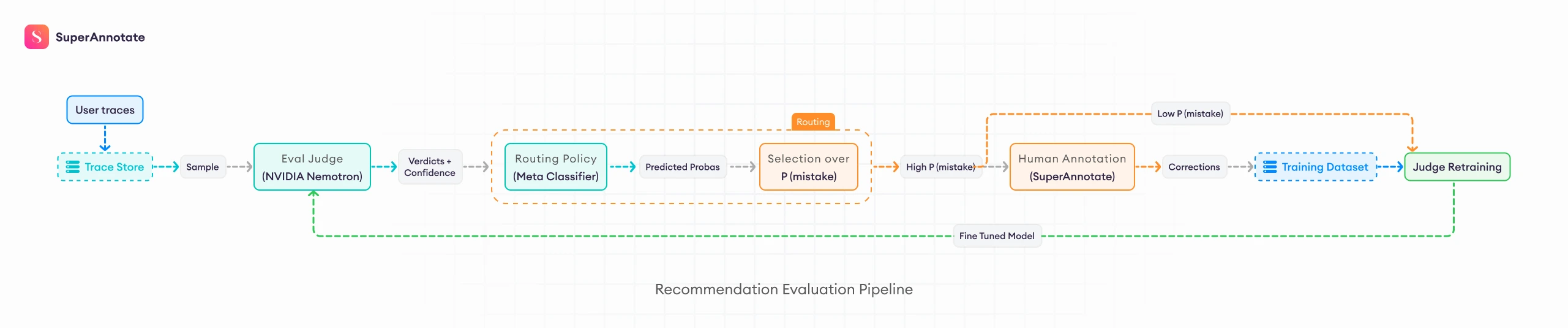
The Solution: LLM Judge and Confidence-Based Human Escalation
Wizard collaborated with NVIDIA and SuperAnnotate to design a hybrid evaluation workflow powered by a customized LLM Judge.
Instead of reviewing every query manually, the system:
- Uses an LLM Judge to evaluate recommendations at scale
- Applies a confidence layer to assess reliability
- Routes only ambiguous or low-confidence cases to human reviewers via SuperAnnotate
This preserves quality where it matters most, while dramatically reducing annotation volume.
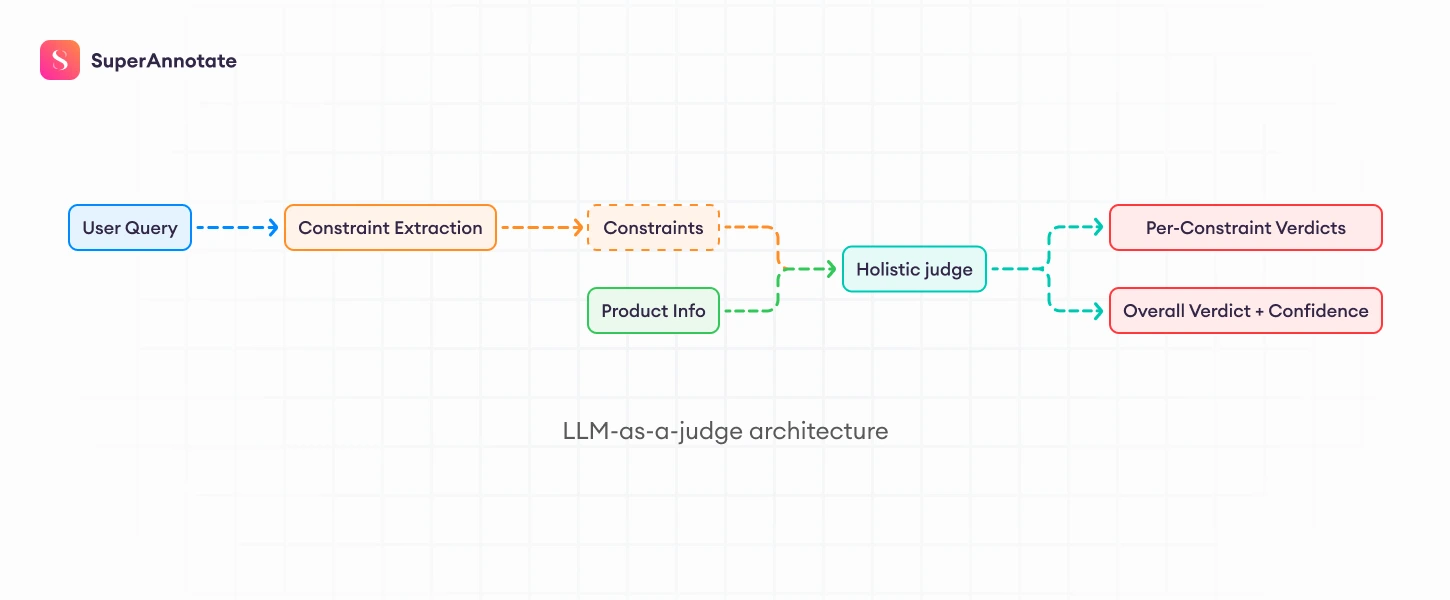
Building a Holistic LLM Judge with NVIDIA Nemotron 3 Nano
Wizard built and customized an LLM Judge powered by NVIDIA Nemotron-3-Nano-30B-A3B.
The architecture works as follows:
- A constraint extraction model identifies explicit and implicit user requirements from the user query.
- The extracted constraints and recommended products are passed to the LLM Judge.
- The LLM Judge evaluates each product constraint independently.
- A structured verdict determines whether the recommendation satisfies user intent.
Using Megatron Bridge, both the constraint extractor and judge models were LoRA fine-tuned on Wizard’s historical with existing evaluation data.
This fine-tuning achieved:
- 91% alignment with human ground truth
- More than 6% points improvement in evaluation accuracy
- A measurable reduction in the gap between automated and human scoring
Fine-tuning the extractor alone yields measurable gains. However, jointly fine-tuning both components produces the highest alignment with human judgement – demonstrating the importance of optimizing the full evaluation pipeline rather than individual modules in isolation.
Accuracy improves progressively when fine-tuning the extractor and further increases when both the extractor and judge are fine-tuned using Megatron Bridge.
"Nemotron's performance as a judge exceeded expectations, closing the gap to human-level accuracy through targeted prompt-tuning.”
- Dave Kale, Head of Machine Learning and AI, Wizard
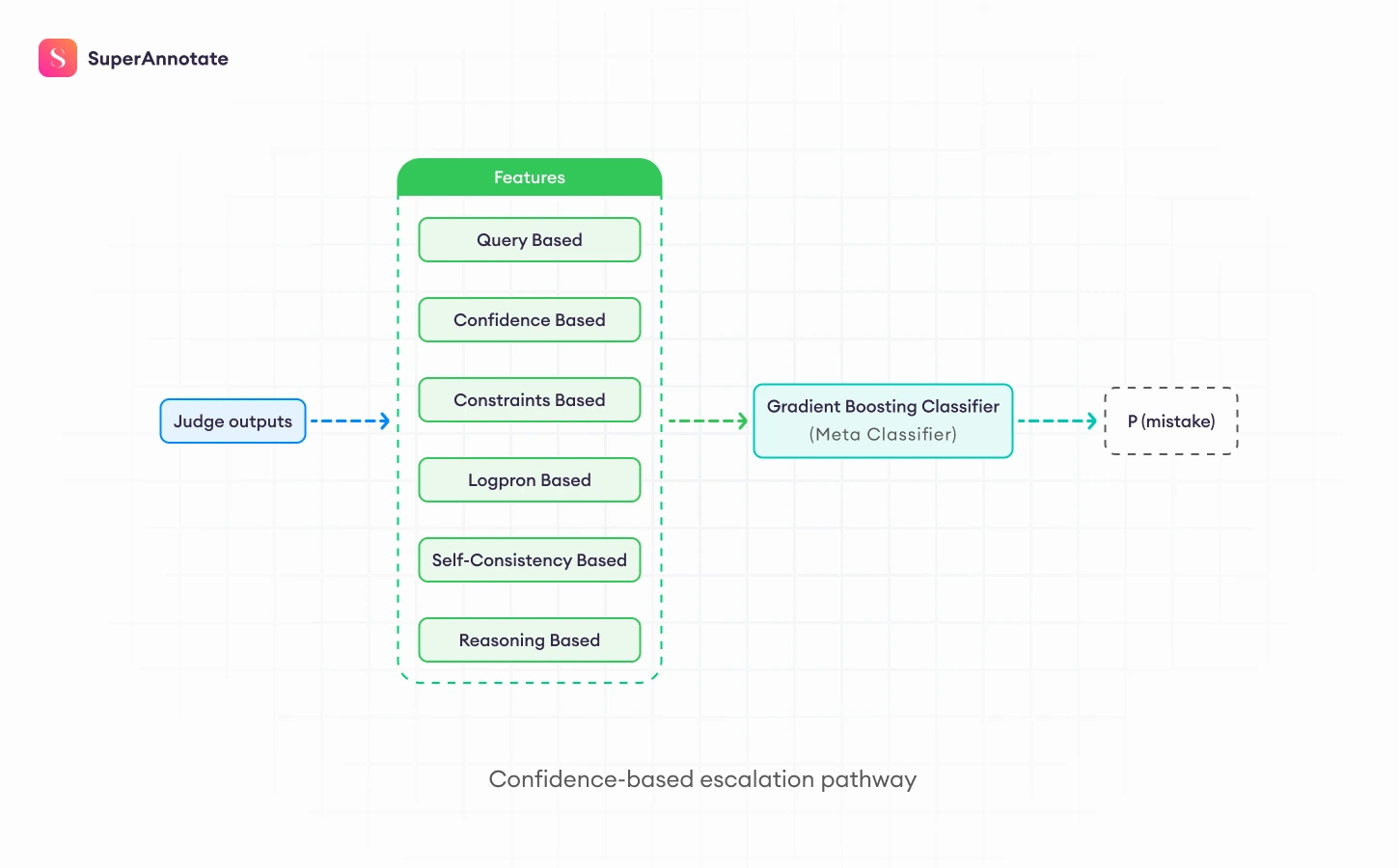
Confidence-Based Escalation: Accuracy Where It Matters Most
To ensure quality remained uncompromised, Wizard implemented a confidence-based escalation pathway that includes:
- Five LLM judges that run on the same inputs using different temperature settings (self-consistency), to get a wider range of outputs for confidence estimation.
- A classifier is then trained on several features, including the model confidence, self-consistency, and more (see diagram) to estimate the confidence level of the evaluation.
- Automatic routing of low-confidence cases to human review in SuperAnnotate.
The design ensures:
- High-confidence cases are handled automatically
- Edge cases receive expert human oversight
- Human feedback continuously improves model alignment
Human review remains the gold standard, but now focused on high-impact scenarios rather than routine validation.
Results: Cost Efficiency Without Quality Tradeoffs
The hybrid human-LLM system delivered significant measurable gains.
- 75% reduction in weekly annotation costs
- 96% accuracy across the evaluation pipeline (residual accuracy)
- 91% alignment with human judgment
- 7% LLM Judge accuracy increase enabled by Megatron Bridge fine-tuning
- Minimal 3.5% quality delta
Importantly, these improvements were achieved without increasing team size. Wizard accelerated throughput while maintaining quality consistency.
Additionally, evaluation outputs are fed back into Wizard’s search and reranking systems – strengthening recommendation performance and increasing user satisfaction.
Better Together: LLM Judge & Human Review
Pairing LLM judges like Nemotron 3 Nano with targeted human oversight gets you the best of both. The AI handles high-confidence evaluations at scale, which frees up your expert trainers to focus on higher-value work.
The practical upside is that your human review capacity stretches further. Instead of manually evaluating everything, reviewers get routed to the complex and ambiguous cases where their input genuinely matters. LLM judges take care of the rest.
"Collaborating with SuperAnnotate and NVIDIA Nemotron has been transformative - scaling our evaluations from a manual bottleneck to a hybrid system that maintains trust while accelerating our launch."
- Devang Kothari, Chief Technology Officer, Wizard
Final Thoughts
Wizard’s journey proves that evaluation does not have to be a tradeoff between speed and quality.
Working with NVIDIA and SuperAnnotate, they brought NVIDIA Nemotron into a human led evaluation pipeline for product recommendations. The result was a system that kept high accuracy while cutting human annotation time by 75%. Residual accuracy stayed above 96%, with over 91% agreement with human judgment. A confidence based escalation step pushed edge cases to expert reviewers, so the team spent time on the hardest calls and the decisions that shaped the system.
The bigger takeaway is simple. LLM Judges work best when they stay tied to expert review. That setup keeps quality steady, improves over time, and makes scaling feel safe.
Build your own evaluation pipeline with SuperAnnotate and NVIDIA Nemotron.


