


LLMs work differently than regular machine learning models, which has created new operational challenges. They're much harder to test, they hallucinate information, and they're unpredictable in ways that normal ML practices can't handle. The industry calls the approach to managing these challenges LLMOps.
Regular ML models fail in clear ways – their accuracy drops or performance gets worse. LLMs can sound completely confident while being totally wrong. They make up facts, misunderstand what you're asking, or give answers that are correct but useless.
In this article, we’ll explain what LLMOps is, how it differs from traditional MLOps, and what practices teams need to successfully deploy and manage LLMs in production.
What is LLMOps (Large Language Model Operations)?
LLMOps, short for large language model operations, covers everything needed to run and manage large language models from start to finish. It includes the steps, tools, and practices that help teams build, launch, and keep these models running smoothly. Think of it as a branch of MLOps (machine learning operations) created for the specific demands of LLMs. The goal of LLMOps is to make it easier to create, deploy, and maintain LLM applications.
What are the Components of LLMOps
Every big shift in machine learning creates new operational demands. Deep learning required new ways of handling compute. Recommendation systems introduced constant monitoring and data refresh. Now large language models are reshaping operational practices again, this time under the umbrella of "LLMOps."
LLMOps breaks the life cycle of a large language model into clear operational pieces. Each stage handles a different part of getting an LLM ready for production and keeping it there reliably.

- Data collection and preparation
Every LLM workflow starts with data. Teams gather text from sources that match the domain: internal documents, public datasets, transcripts, code, or customer interactions. Once collected, the data has to be cleaned and normalized. Duplicates, irrelevant entries, or inconsistent formats get removed. The goal is a dataset that a model can actually learn from.
- Prompt engineering and embedding management
Prompts are how you tell the model what you want. Teams build and iterate on prompts, examples, and instructions to shape outputs for real use cases. In parallel, embeddings are created to handle search and retrieval, turning text into vectors so the model can pull in relevant context later. Both prompts and embeddings need management – they evolve, break, and get replaced as the system matures.
- Fine-tuning and adaptation
Almost no business runs base models as-is. They fine-tune with domain-specific data or run lightweight adapters like LoRA to teach the model vocabulary, tone, or reasoning for a specific task. Sometimes this involves training smaller “expert” models that plug into a larger workflow. This step ties the generic power of a foundation model to the reality of your product or industry.
- LLM chains and agents
Once a model can handle your tasks, you rarely just send it one prompt and take one answer. You chain models, tools, and retrieval calls together. An LLM agent might break a request into steps, call external APIs, or decide when a human needs to weigh in. This orchestration layer turns the LLM into something that can run actual workflows instead of just returning a text out response.
- Evaluation and testing
Models have to be tested before they’re trusted. This means structured evaluations with rubrics, side-by-side comparisons of versions, automated checks for toxicity or bias, and human review for harder edge cases. This is also where domain experts weigh in. Their judgments create the ground truth that determines whether the model is meeting expectations.
- Deployment, serving, and monitoring
Once the model is ready, it gets deployed either via an API, as a container, or inside a product pipeline. From there, it needs monitoring. Teams track latency, cost, and, most importantly, output quality. They look for drift (when the model’s behavior changes over time), watch for failures, and feed those findings back into the data and evaluation steps.
- Governance and security
Throughout all of this, there’s a layer of oversight. Teams manage who can access which models, what data is being logged, and how sensitive information is handled. Closed models often provide built-in compliance features. Open-source deployments mean those controls have to be built in-house. Either way, governance keeps the system auditable and defensible.
LLMOps vs. MLOps
LLMOps is a category of MLOps, but it has major differences. LLMs are much larger, complex, and often behave in less predictable ways. Therefore, the way you evaluate, manage, and monitor LLMs is fundamentally different. You’re working with systems that generate language instead of sole scores, and that changes how you operate them.
Here are the key differences.
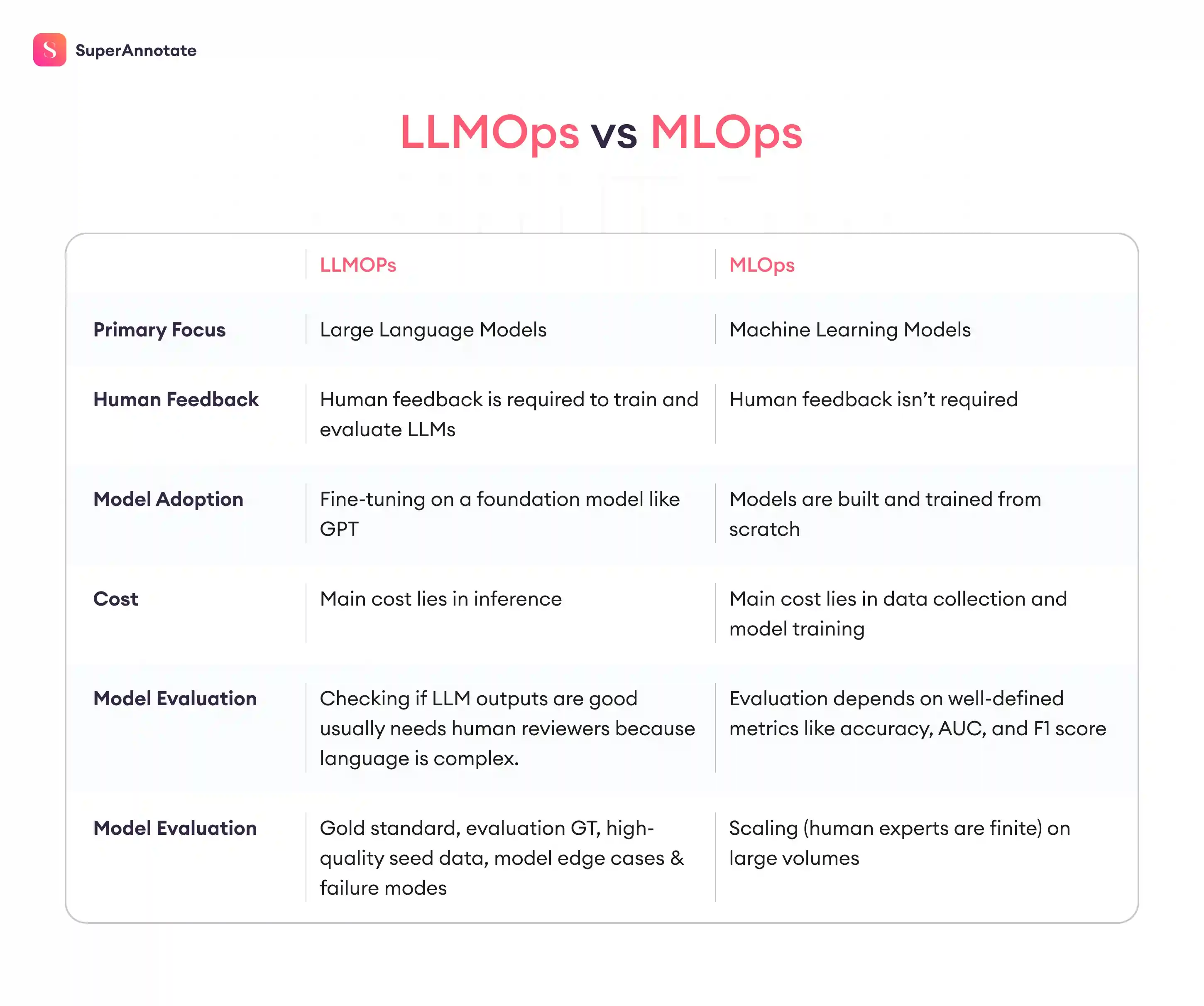
- Evaluation depends on human feedback instead of fixed metrics
In MLOps, you track accuracy, loss, and drift using standard datasets. In LLMOps, quality is much harder to measure. You often rely on human reviewers to judge whether an output is factually correct, useful, or appropriate. Teams need custom eval sets, subjective rubrics, and feedback loops to catch issues like hallucinations. There’s no single score that tells you if your LLM is working well; you will have to look at patterns in behavior.
To catch that, you need feedback from subject matter experts who can say whether the output is helpful, safe, or usable. That means building feedback collection into your workflow, labeling model outputs, and tracking quality over time. For enterprise-scale AI projects, you’ll need a data platform like SuperAnnotate to turn domain expert knowledge into AI-ready data and evaluation workflows, and have full visibility into the projects. The evaluation layer is the backbone of any LLM application, and its lack is where most product failures come from.
- You adapt models you didn’t train
MLOps usually involves training models on your own data from the ground up. In LLMOps, you start with a pretrained model that’s already been trained on a broad corpus. You don’t control how it was trained or what data it saw.
To make the model useful, you adapt it to your domain through prompts, fine-tuning, or retrieval. But you’re shaping behavior from the outside, often without insight into the internal structure. That makes versioning, prompt tracking, and output monitoring essential, otherwise, you won’t know what changed when things break.
- Inference is heavier, slower, and more expensive
ML models can often run on CPUs with low latency. LLMs typically require GPUs and tuning for things like batching and token streaming. Cost per request becomes a real concern, especially at scale. You need to make decisions like whether to route basic queries to smaller models or cache common outputs. In MLOps, infra matters. In LLMOps, it becomes a gating factor.
- You monitor for behavior, not just performance
ML monitoring tracks things like model accuracy and input drift. In LLMOps, you also watch for problematic outputs — hallucinations, bias, harmful suggestions. This expands the surface area you have to monitor. It’s not just about “did the model fail,” but how it failed and what it said when it did.
How to Bring LLMs into Production: 3 Phases of LLMOps
Getting an LLM into production means building a setup that supports customization, quality control, and ongoing performance checks. It’s less about picking the “best” model and more about putting the right systems around it.
Here are the parts that matter most:
Choosing between open-source and private LLMs
Open-source models give you control. You can host them on your own infrastructure, which means sensitive data stays in your environment and you set the rules for security. They can be fine-tuned for your domain and optimized for specific use cases. The tradeoff is the work involved – you manage scaling, updates, and safeguards.
Private models like GPT‑4 or Claude are delivered as APIs. You don’t handle hosting or maintenance, which speeds up deployment, but every query leaves your system and goes through a third-party provider. That means higher costs at scale and limited control over how the model evolves.
The decision depends on what your team needs: open-source works better when control and customization are priorities. Private models work better when simplicity and time-to-market matter more.
Training LLMs for a specific domain
Off-the-shelf models don’t understand your industry, your product, or your tone. If you want them to perform well, you need to shape how they see the problem. That can mean prompt engineering, in-context learning, RAG setups, or LLM fine-tuning.
The key is starting with high-quality inputs. This includes curated examples, clear system instructions, well-defined success criteria, and edge cases that reflect actual user needs. Domain experts play a big role here – what they know becomes the foundation for high-quality training data.
SuperAnnotate is designed to turn that knowledge into AI-ready data. You can build interfaces that guide experts through annotation, QA, and eval tasks. The platform supports rich instructions, custom schemas, and full visibility into task progress and reviewer alignment.
Evaluating and monitoring LLMs
You don’t know how well a model works until you measure it – consistently, across the real cases it’s expected to handle. This is the LLM evaluation and testing stage – scoring outputs against defined rubrics, running comparisons across versions, tracking drift, and escalating unclear cases to the right reviewers.
SuperAnnotate lets you manage this entire process in one place. You can combine automated LLM scoring with human review, set up evaluation tasks with custom UI, and route outputs based on confidence thresholds or disagreement.
The platform tracks reviewer agreement, task throughput, prompt-level failure patterns, and model performance over time. All of this shows up in clean analytics dashboards, so you can actually act on what the data is telling you.
Without this level of structure, it’s almost impossible to track model performance in live settings. A good evaluation and monitoring setup is what keeps LLM performance in check.
LLMOps Business Benefits and Adoption Strategies
LLMs are changing how businesses operate, but simply ‘using’ them doesn’t automatically lead to results. To get real value, companies need clear, practical ways to manage and scale LLM applications. This is the essence of LLMOps.
Practical Benefits of LLMOps
- Faster Innovation:
LLMOps simplifies the workflow from idea to production. Automating routine tasks like model updates and evaluations allows teams to quickly experiment and roll out new features.
Example: A retail company uses LLMOps to automate chatbot updates, enabling them to launch new customer service features in days instead of weeks. - Reduced Costs and Better Efficiency:
LLMOps helps teams identify and eliminate wasted resources, such as unnecessary manual checks or duplicated efforts. Automated monitoring and management tools lower operational costs and free up your team to focus on important tasks. - Early Risk Detection:
Regular evaluation and monitoring help you spot problems like model drift, incorrect outputs, or performance dips early, reducing the likelihood of costly errors in production.
Example: In a finance setting, automated monitoring flags unusual output from a loan approval model, allowing the team to intervene before any compliance issues arise. - Better Team Collaboration:
With standardized practices in place, data scientists, engineers, and business stakeholders speak the same language. Clear processes and responsibilities mean fewer misunderstandings and faster project delivery. - Scalable Operations:
LLMOps allows you to manage multiple models, data sets, and user requests smoothly. You can easily expand usage without losing oversight or quality.
Importantly, LLMOps is not a “set and forget” solution. It encourages ongoing optimization. As your business needs change, LLMOps practices help you adapt and improve your AI operations over time.
How to Adopt LLMOps in Your Organization
- Don’t Chase Use Cases – Chase Pain Points:
A good LLMOps rollout shouldn’t start with “let’s build a chatbot.” It should start with a business problem that’s painful and expensive – like regulatory reporting, customer churn, or fraud detection.
- Start Small, Then Grow:
Launch a focused pilot project first. Pick a clear business problem, turn it into an impactful use case, measure outcomes, and learn before expanding LLMOps practices more widely.
- Equip Your Team with Training:
Give your team practical training through workshops, hands-on sessions, or expert consultations. Making sure everyone understands LLMOps basics will drive faster adoption and results.
- Standardize Workflows:
Document templates and clear guidelines for common tasks like deploying models, monitoring outputs, and managing updates. Standard workflows make onboarding easier and reduce mistakes.
- Encourage Cross-Functional Collaboration:
Create integrated teams with members from data science, engineering, product, and business units. This cross-functional approach ensures projects align with business goals and run smoothly.
- Continuously Monitor, Refine, and Mitigate Risks:
Set up straightforward monitoring systems to track how well models perform, associated costs, and potential risks. Regularly review this data and adjust your approach to keep improving and to proactively address any emerging risks.
Adopting LLMOps is a journey that builds continuous improvement and risk mitigation into your AI operations. For businesses serious about leveraging generative AI, LLMOps provides a structured path to delivering consistent value.
The Future of LLMOps: AgentOps
LLMOps today mostly means getting an LLM into production, keeping it evaluated, and catching problems before they scale. That won’t stay the full picture for long.
LLMs are moving from standalone models to systems of models and tools. Chains are already common. Agents – LLMs that act on their own, call APIs, or hand off tasks – are becoming the next layer. Running these agent systems creates a new discipline many are starting to call AgentOps.
AgentOps is about managing how multiple models, tools, and decision layers work together. It means tracking what the agent did, what data it used, and why it made a certain call. Without that visibility, debugging an agentic workflow becomes unnecessarily hard. Think of it as the same discipline LLMOps brought to single-model pipelines, but now stretched across many moving pieces.
At the same time, companies are looking at GenAIOps – a broader term for operational practices across all generative AI systems, not just text models. As multimodal AI rises and companies mix text, image, audio, and video models, they need shared infrastructure for governance, evaluation, and monitoring across them all.
The result is that LLMOps won’t stay in its own silo. It’s turning into the base layer for AgentOps and GenAIOps. The evaluation workflows, data pipelines, and monitoring that work for one model will need to scale to multi-agent systems, multi-modal models, and products that combine all of it.
Platforms like SuperAnnotate already sit at the center of this shift. The same features that support LLM evaluation today – human review, custom workflows, detailed analytics – are what will keep agentic and multimodal systems accountable tomorrow.
The future of LLMOps isn’t just “more of the same.” It’s preparing for a world where models are making decisions in chains, sharing context across systems, and running parts of your product automatically. The teams that treat LLMOps as a living foundation will be the ones ready for what comes next.
Final Thoughts
Using large language models brings new challenges compared to traditional machine learning. The biggest difference is that they are generative models and their outputs are unpredictable, and trickier to test. LLMOps helps address this by providing practical ways to manage prompts, evaluate outputs with human input, track performance, and ensure transparency.
As LLMs grow more advanced, LLMOps will naturally evolve into practices like AgentOps and GenAIOps, which manage multiple interacting models and different types of AI systems.

Common Questions
This FAQ section highlights the key points about LLMOps.

