


General language models like GPTs work well for broad tasks, but they struggle with specialized domains. They don't understand niche industries, their jargon, and can't access proprietary knowledge that makes your business unique. When you need AI that really understands your specific field, you should go for domain-specific LLMs (DSLMs).
Gartner reports that one of the two biggest movers in AI that sits on inflated expectations is AI-ready data.
"To scale AI, leaders must evolve data management practices and capabilities to ensure AI-ready data — determined through the data’s ability to prove its fitness for use for specific AI use cases — can cater to existing and upcoming business demands. However, 57% of organizations estimate their data is not AI-ready. Organizations without AI-ready data will fail to deliver business objectives and open themselves up to unnecessary risks." - Gartner
Domain-specific models solve these problems by training on curated datasets from your industry. But building them brings new challenges. You need high-quality training data, which means finding domain experts who can label and validate datasets. You need the right infrastructure to train and deploy models efficiently. You need to ship fast, which means using both automated evaluation and human reviewers. And you need the right training and evaluation tools to make all of this come true.
The tooling landscape for domain-specific LLMs is still evolving. Some teams build everything from scratch. Others use off-the-shelf tools that handle data management, model training, and evaluation. The choice depends on your team size, technical capabilities, and how much control you need over the process.
In this article, we’ll learn about domain-specific LLMs, how to build them, and what practices to follow.

What is a Domain-Specific LLM?
A domain-specific LLM is a large language model that has been trained on data from a specific industry to perform relevant tasks in that domain. Unlike general-purpose models that are broadly trained on Internet data and don’t know the specifics of a niche business, domain-specific LLMs are trained to master distinct domains like finance, law, medicine, etc.
Why Do You Need a Domain-Specific LLM?
A domain‑specific LLM shapes the model’s thinking. A general model soaks up everything from the Internet and then spreads that knowledge thin. When you ask it about a contract clause or a diagnostic report, it doesn’t have much depth to draw on. It guesses. Sometimes the guess is close enough. Sometimes it’s wrong but sounds right, which is worse.
When you build a model on the materials that live inside one field, the way it reasons shifts. It doesn’t just “know” the vocabulary – it understands why the words are used and what they signal. A phrase in an engineering spec might mean “stop production.” A line in a medical chart might mean “get someone into surgery now.” A general model sees text; a domain model sees meaning the way the people in that field do.
And then there’s trust. If you rely on a model to support doctors, analysts, or lawyers, you need it to know you can trust it. A domain‑specific LLM has fewer gaps to fill because it has seen more of the real situations it will face. That means less guessing and more answers that feel more like they came from someone who actually does this work every day.
The “why” is simple: a model built for everything is great for nothing in particular. A model built for one thing becomes a partner in that work: it shares the instincts, the caution, and the judgment that come from living inside that world.
How to Build a Domain-Specific LLM?
There are two main approaches to creating a domain-specific language model. You either train one from scratch, or you start from a pretrained foundation model and adapt it to your domain. The first is rarely practical; teams almost always fine-tune an existing model because most of the linguistic and reasoning capability needed for domain work already exists in foundation models.
Training from scratch requires large-scale data that reflects both general and domain-specific language, along with significant compute. Even for large enterprises, this route is usually reserved for cases where they need complete control over model behavior and architecture, or where the target domain is extremely far from anything a foundation model has seen (which rarely happens).
In most cases, adapting an existing model is more efficient and more effective. This gives you access to high-quality general language understanding and reasoning, and lets you focus on shaping the model around your domain-specific constraints.
There are a few primary techniques used to specialize foundation models for domain-specific behavior. Each comes with its own tradeoffs in terms of depth, cost, flexibility, and long-term maintainability.
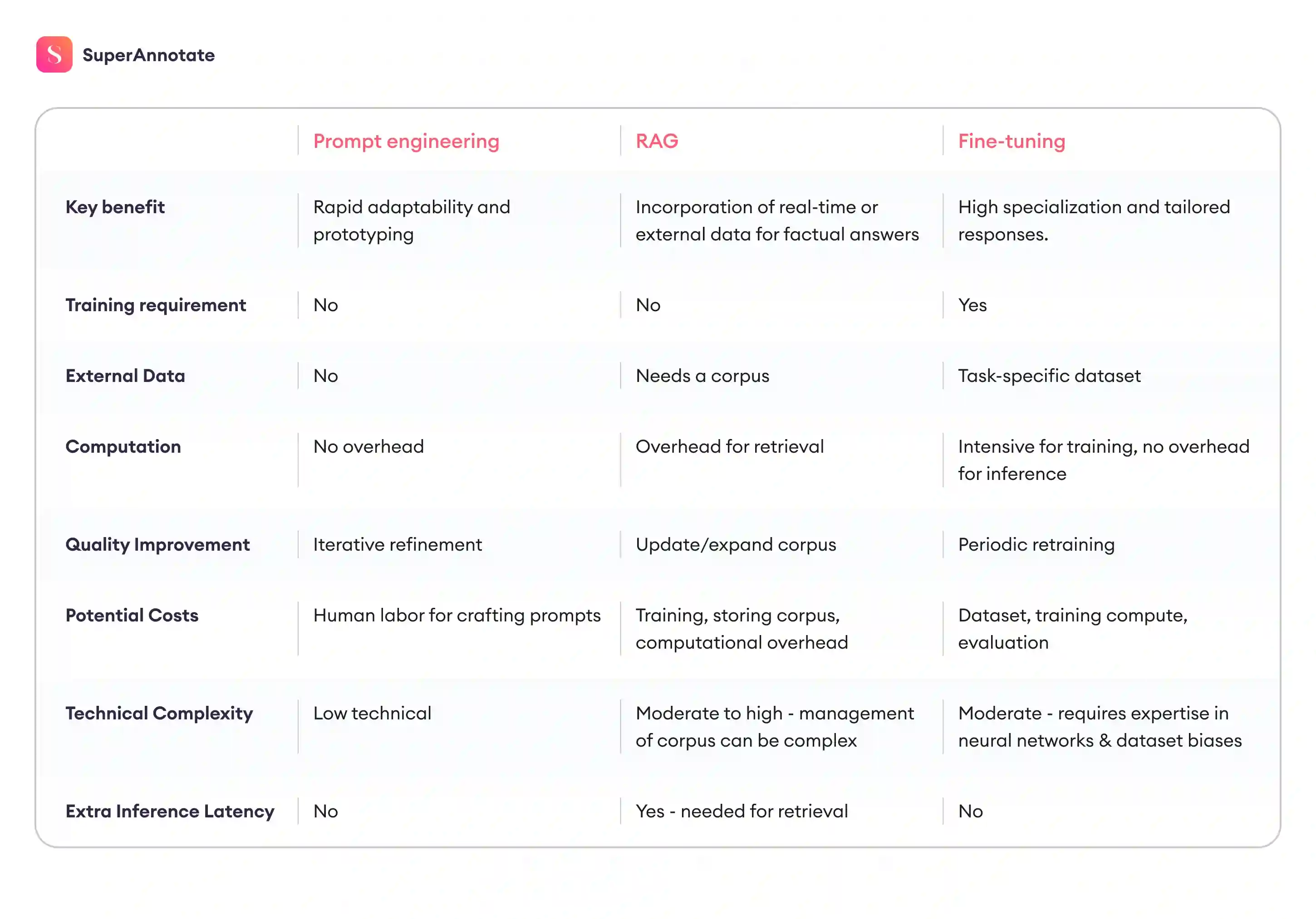
Prompt Engineering
Prompting is usually where people start. You can get surprisingly far by just shaping your inputs carefully. It's popular because you can quickly get better results with minimal effort. OpenAI researchers have consistently shown that effective prompts boost domain-specific performance, especially for initial testing or straightforward tasks.
However, prompt engineering alone rarely solves the deeper, more nuanced problems in specialized domains. Ethan Mollick pointed out its limitations and that while prompts work well initially, they’re just a starting point when more complexity or precision is required. If you need your model to consistently handle nuanced or complex reasoning, prompt engineering alone won’t get you there. It’s a useful first step, excellent for exploring a model’s capabilities or quick prototyping, but deeper accuracy usually requires more substantial methods.
LLM Fine-tuning
LLM fine-tuning is one of the most direct ways to adapt a model to a specific domain. You take a base model and show it examples that reflect the actual tasks it needs to perform, written in the language your experts use.
This changes the internal behavior of the model. Instead of relying only on general patterns, it starts to reflect the logic and terminology used inside your organization. That includes how questions are asked, how ambiguous information is handled, and what counts as a complete or acceptable answer.
The data for fine-tuning usually comes from internal documents, which are almost never ready to use off the shelf. They need structuring, cleanup, or re-annotation. This is where expert input and the data platform become essential.

SuperAnnotate offers teams a domain data platform to build fine-tuning datasets to train your models. With customizable annotation interfaces and AI-powered automations, your domain experts can create high-accuracy training data and evaluate model output.
Once the dataset is shaped, teams apply either full fine-tuning or lighter methods like LoRA adapters. The result is a model that behaves much closer to how your experts would.
Andrej Karpathy explained that success in fine-tuning largely comes down to using the right data, not necessarily large volumes, but carefully curated and annotated examples. Teams that succeed often engage domain experts to identify critical, nuanced examples and guide the training process. This hands-on approach translates directly into an improved model reliability and accuracy.
Transfer learning
Think of this as fine-tuning with a bit more structure. Instead of jumping from a general-purpose model straight into a narrow domain, you train in stages – general → related → specific. So if you're building a model for cardiology, you first adapt it to broader medical literature, then go deeper.
Transfer learning works well when your end domain is very narrow or when you don't have much final-task data. It lets the model pick up relevant framing before it gets into the weeds. Google’s Med-PaLM followed this pattern, and it’s something Stanford’s CRFM group has talked about a lot. The key is not overdoing the intermediate stages. Each step needs to make sense contextually, or you risk introducing drift.
RAG (retrieval-augmented generation)
Sometimes you don’t want the model to train on data – you want it to know how to look things up in it. RAG connects a model to an external knowledge source so it can pull in relevant context at generation time. This makes a huge difference in domains where facts change often or when the model needs to reference long, specific documents.

What matters here is your retrieval pipeline. If your search index is weak or your chunking is off, the model pulls the wrong things. This is why teams need to evaluate their RAG systems and their components – retriever, reranker, and the language model. The best practice after evaluating and finding the weak component is then fine-tuning that exact RAG component. You then do the final evaluation, and the already accurate and reliable RAG system will free you from the headache of retraining every time the domain shifts.
LLM and Agent Evaluation
This is where most teams underinvest. Getting a domain-specific model to work is one thing; knowing how well it works and where it breaks is harder. You can’t rely on generic benchmarks because they don’t reveal your data and your business. You need evaluation sets built with people who understand the field – people who can look at a borderline answer and tell you whether it’s acceptable, misleading, or outright wrong.
Good LLM evaluation means a feedback loop, not a one-round QA pass. You want outputs reviewed both for correctness and for context. Those examples feed right back into your training or prompt strategies. Teams that close that loop quickly tend to iterate faster and end up with more reliable models in production.

SuperAnnotate helps teams thoroughly evaluate and test their models both in training and production. Our platform offers fully customizable evaluation UI and workflows, automation, and project/people management. With SuperAnnotate, teams easily build their evaluation workflows and ship safer and more accurate models in seconds.
Best Practices for Adapting an LLM to Your Domain
It’s easy to mess up the domain adoption process if not follow certain practices. Common mistakes include trying to heavy lift in the beginning, overlooking the human component of training and evaluation, and using inefficient tools or spreadsheets to manage large-scale data. Here’s what to do instead:
Start Small
Early results improve fastest when the task is focused. A model trained to handle one contract type or one support intent will outperform a more general one, even on narrow tasks. Small, well-designed datasets often outperform large but scattered ones. Choosing one problem, collecting examples that fully reflect it, and building evaluation criteria specific to it makes early iterations more useful.
Involve Domain Experts
Domain experts are your most valuable assets, and they decide the quality of your AI model. However, they can't contribute effectively unless the tooling meets them where they are. SuperAnnotate helps domain experts work faster and smarter by letting you build fully customized annotation UIs and review workflows, integrated directly into your AI stack.
- Interactive custom multimodal UIs show just the context needed for complex edge cases.
- Spreadsheet-style QA views let experts quickly review large datasets.
- Custom routing rules send only the right data to the right expert at the right time.
- Python SDK and containerized scripts push expert-reviewed data into your training loop.
Double Down on Data Quality
Everybody knows how important data quality is for AI models. But achieving that quality is hard. You need data that perfectly represents your niche, is well-structured and curated, and is built by domain experts. Where your data sits is also crucial – spreadsheets and internal tools might stall if your data scales. You need a perfectly traceable and transparent system where mistakes are found, fixed, or relabeled as needed. The truth is – models live on data, and ensuring quality has a lot to do with the data platform and partner you choose in the long run.
Domain Specific LLM Examples
Most enterprises building domain-specific LLMs are working within fields that already have some form of structured or semi-structured domain data: scientific publications, proprietary knowledge bases, internal reports, chat transcripts, and domain-specific APIs. How this data is used depends on both the type of domain and the specificity of the tasks involved.
Chinese researchers recently did a study on injecting domain into general LLMs, and here are the discussed fields and the domain adaptation techniques.
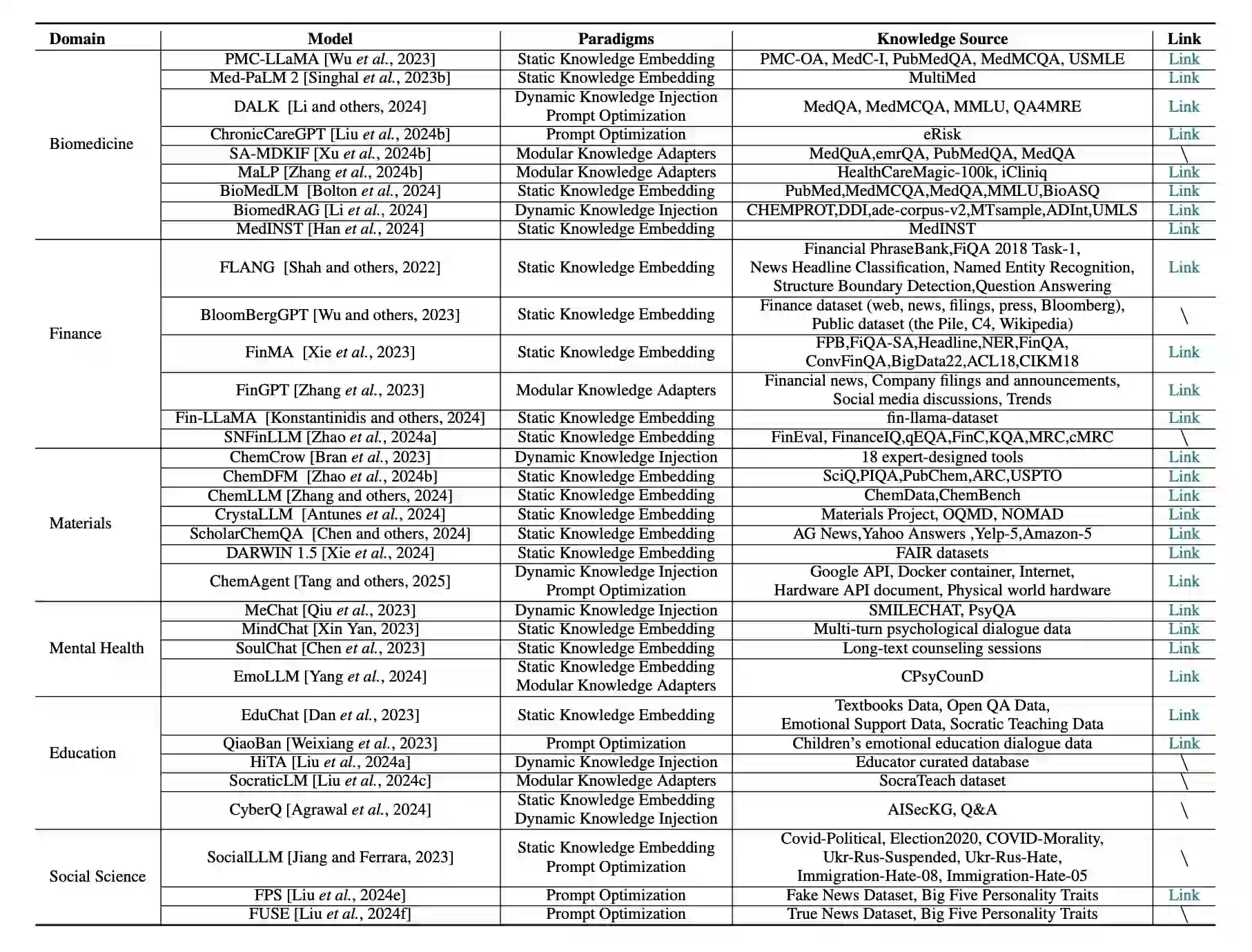
Biomedicine
Biomedicine is a textbook example of a domain with both data depth and performance constraints. Models here are often built on top of open-source foundation models, then pretrained using massive datasets like PubMed. This static embedding approach gives the model internal access to vocabulary, clinical phrasing, and task-specific reasoning that general-purpose models don’t cover.
Once the base familiarity is built, fine-tuning is done on more structured medical tasks: QA, summarization, instruction following, or form completion. In some cases, models are also paired with tool-use agentic capabilities – for instance, integrating access to online biomedical APIs for live lookup of genes or terms. This hybrid design helps models reason with static internal knowledge while also pulling in the latest information at inference time.
Instruction tuning plays a key role here. Instead of training the model on raw documents, teams use prompts and responses that match the way clinicians or researchers might ask questions. The goal is to build behavior that matches how domain professionals think and work.
Finance
Financial models follow a similar pattern but with different data sensitivities. Many teams start with LoRA-based fine-tuning on instruction-style examples: customer communication, sentiment tagging, transaction reasoning, or risk assessment. These samples are often short, domain-specific, and packed with jargon that doesn’t generalize well across industries.
What’s changed recently is that more teams are pairing these methods with purpose-built evaluation pipelines. A model that answers questions about equity exposure or portfolio drift needs to be judged for correctness, completeness, and interpretability. This kind of scoring is nearly impossible to automate with metrics alone, which is why evaluation loops, especially ones involving domain experts, are becoming embedded into the development process.
Scratch-trained financial models do exist, but most of the value in these systems comes from highly targeted fine-tuning and well-scoped task instruction. Smaller training sets, built with internal data and reviewed by experts, are often more effective than broad-scale retraining.
Materials and Chemistry
In fields like materials science or chemistry, the task landscape is more fragmented. Many of the most useful systems here operate with modular tool integrations. Instead of relying purely on language model pretraining, they inject knowledge from external simulation tools, structured chemical databases, or planning engines.
Training tends to focus less on embedding full corpora and more on prompt structuring, planning, and chaining reasoning steps across tools. Some models are trained using two-phase processes: a first round to align with natural scientific text, followed by a second to teach the model to coordinate actions or tools in real-world lab scenarios.
There’s also growing interest in modular adapter strategies – lightweight parameter sets that specialize the model for certain chemistry subfields, without retraining the full backbone. These approaches give teams more flexibility to deploy and version models across experimental tasks without managing separate model forks.
Final Thoughts
General-purpose models make a strong starting point, but they rarely meet the quality bar for real enterprise use. Domain-specific LLMs step in where those models stall – handling tasks that demand niche knowledge and precision.
Building one means getting the right data in place, making space for domain experts in the loop, and setting up systems that grow with your use case. Every part of the process – curation, annotation, training, evaluation – has to reflect the reality of the work the model supports.
SuperAnnotate helps enterprises get there faster. By giving domain experts and ML teams one environment to curate, annotate, and evaluate data, it shortens the path to high-quality, domain-specific models that hold up in production.
A model trained on your field, with your data and your people behind it, is what moves AI from generic to genuinely useful.

Common Questions
This FAQ section highlights the key points about domain-specific LLMs.

