


LiDAR(Light Detection and Ranging) is a remote sensing technology that uses lasers to measure distances and generate precise three-dimensional information about the shape and characteristics of its surrounding objects. LiDAR systems are used in a variety of applications, including autonomous vehicles, aerial mapping, surveying, environmental monitoring, etc. Furthermore, they are particularly useful in situations where high-precision and high-resolution information about the shape and location of objects are required.
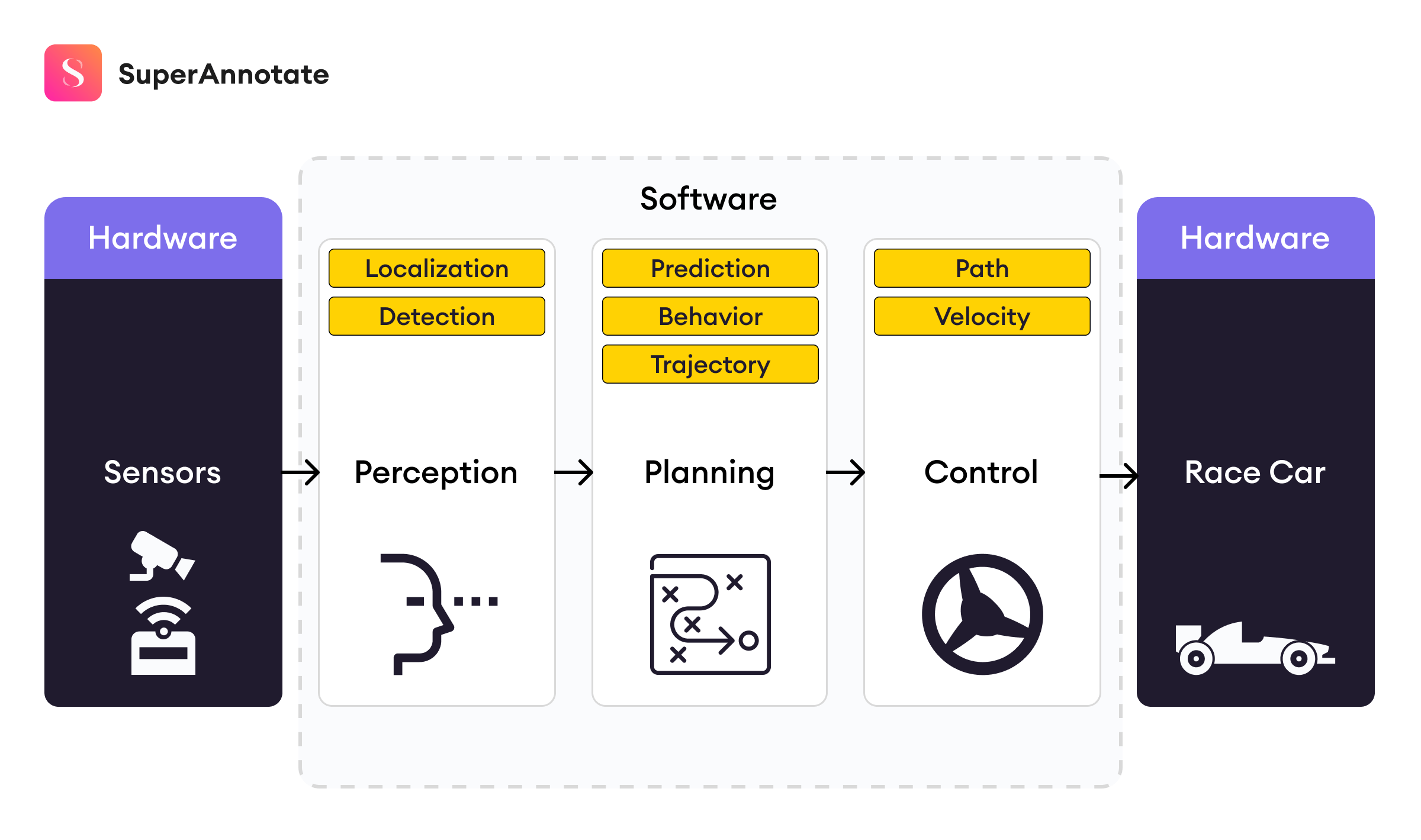
Autonomous vehicles heavily rely on input data to make driving decisions. Logically, the more detailed the data, the better (and safer) the decisions made by the vehicle. While modern cameras can capture very detailed representations of the world, the 2D nature of the output does limit the perception of important aspects of the 3D world, and the depth of surrounding objects is one of them.
To address such issues, there is a whole direction of research in computer vision for depth estimation from RGB images. State-of-the-art deep learning architectures are employed to estimate the depth of each object in an RGB image. These models achieve reasonable performances and are readily employed in indoor autonomous agents, such as household assistant robots. All things aside, these models yet fail to solve the problem for autonomous vehicles as their error of depth estimation is pretty high, considering the speed of vehicles and the damage that car accidents can cause.
However, at the same time, cameras are limited in their capacity to capture information. For example, the rain may make the image almost useless while a lidar instrument will still capture information. This demonstrates that cameras might not work in all environments or circumstances, and since autonomous vehicles are a particularly risky and high-impact use case of neural networks, it is important to make sure that the networks we build are as robust as possible, and how does it all start? With the right data. Ideally, we want our network to get 3D point data as input since it needs to make predictions about the 3D world. This is where LiDAR comes in.

This article aims to provide a gentle yet thorough introduction to LiDAR technology, its use cases in artificial intelligence, the overview of the pipeline from collecting LiDAR data to getting an artificial intelligence model operating with it, and finally, the way SuperAnnotate can help with your LiDAR data. Once you reach the end of this article, you will have a grasp of the following:
- What LiDAR is and how it works
- What is in a collection of LiDAR data
- How neural networks work on LiDAR data and what challenges they face
- Common applications of LiDAR data
- How LiDAR data differs from 2D images and how the annotation process changes
- How SuperAnnotate can help with annotating a stream of LiDAR data
What exactly is LiDAR?
LiDAR stands for light detection and ranging. LiDAR technology has been used since the 1960s when it was being installed on airplanes to scan the terrain they flew over. LiDAR grew more popular in the 1980s with the advent of GPS, when it started being used to calculate distances and build 3D models of real-world locations. To specify, LiDAR is a remote sensing technology that uses light in the form of laser pulses that measures distances and dimensions between the sensor and target objects. In the context of autonomous vehicles, LiDAR systems are used to detect and pinpoint the locations of objects like other cars, pedestrians, and buildings close to the vehicle. The rising popularity of artificial neural networks has made LiDAR technology even more useful than before.
How does LiDAR work?
When breaking it down, most LiDAR systems consist of four elements:
1) Laser: Sends light pulses toward objects (usually ultraviolet or near-infrared).
2) Scanner: Regulates the speed at which the laser can scan target objects and the maximum distance reached by the laser.
3) Sensor: Captures the emitted light pulses on their way back, when they are reflected from the surfaces. Measuring the total travel time of a reflected light pulse, the system estimates the distance of the surface from the lidar system.
4) GPS: Tracks the location of the LiDAR system to ensure the accuracy of the distance measurements.
Through recent advancements, modern LiDAR systems can often send up to 500k pulses per second. The measurements stemming from these pulses are aggregated into a point cloud, which is essentially a set of coordinates that represent objects that the system has sensed. The point cloud is used to create a 3D model of space around the LiDAR.

Types of LiDAR systems
There are two general types of LiDAR systems: airborne and terrestrial, and since our use case of interest is autonomous vehicles, we'll mainly be focusing on terrestrial LiDAR.
Terrestrial LiDAR is attached to objects fixed to the ground and scans in all visible directions. They can be static (e.g., attached to an unmoving tripod or a building) or mobile (e.g., attached to a car or a train).
Nowadays, LiDARs are widespread, finding their place also in the latest mobile phones like Apple iPhones or Samsung devices. These commodity LiDAR sensors allow a wide range of augmented reality apps to provide even more utility for people, while their application in safety-critical areas is still limited as they provide low-quality and sparse data. Their pricey counterparts like Velodyne HDL-64E or Velodyne HDL-16E are more bulky devices mounting on them 64 and 16 lasers respectively, providing highly precise and denser point clouds that describe the surrounding environment in great detail.
Collection of LiDAR data
When comparing LiDAR data with other modalities like images, videos, audio, or text, we see that there is a very small number of LiDAR datasets that are publically available, although the usage of LiDAR systems dates back to the 1960s. The reason behind this issue is the difficulty of both the acquisition and annotation process of LiDAR data. Because even high-end LiDAR systems provide sparse and colorless point cloud data, one adds also sensors of other modalities (usually cameras) when collecting LiDAR data.
The curse of sparsity can make the appearance of very different but far from the system objects very similar. For example, a person standing close to the edge of the sensing radius of a LiDAR system can be indistinguishable from a small tree for a human annotator. High-quality images from the cameras accompanying the LiDAR systems solve this issue.
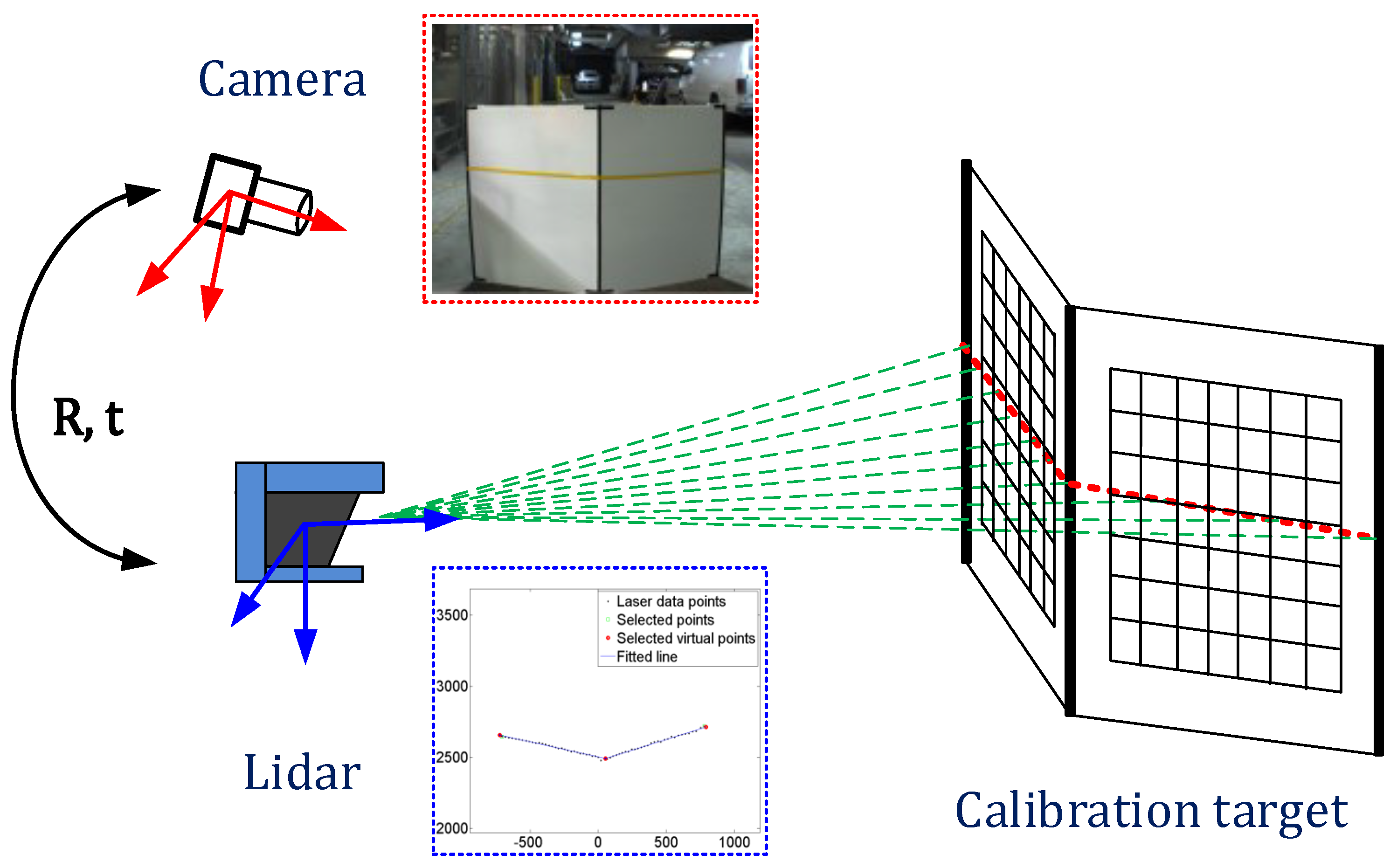
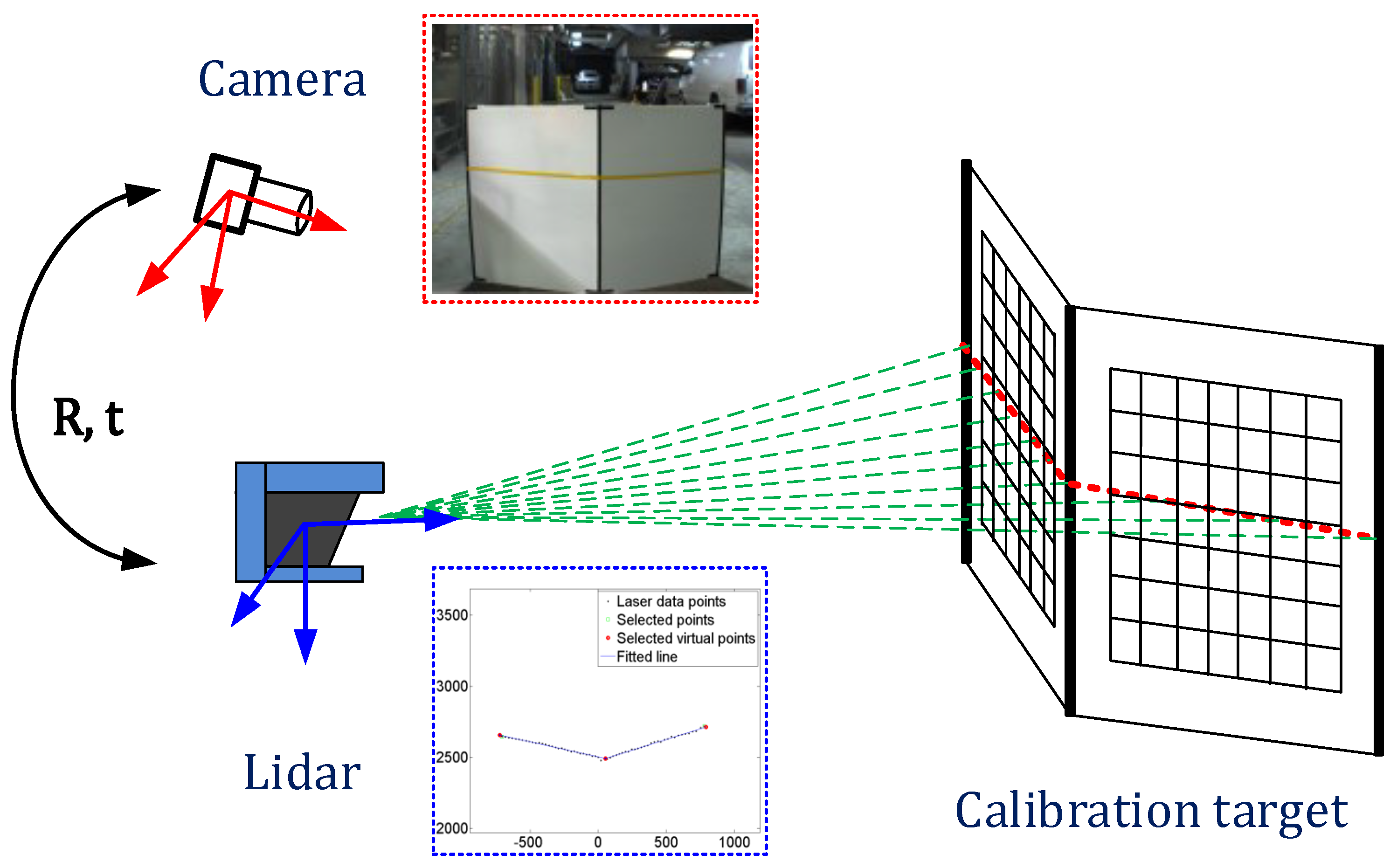
The described solution looks simple and easy to do, but in reality, the calibration of these sensors together is a tedious task. The so-called sensor fusion is achieved by ensuring a precise and fixed position of the sensors, then using those positions, sensor-specific parameters - called intrinsics, undergo complex alignment routines which usually involve big printed chessboard images placed at various angles relative to the sensors.
{kind=link}
As a result, one obtains an extrinsic matrix which is used in combination with camera intrinsic matrices to project points from the point cloud to pixel space and vice versa. This two-way connection between sensors not only enables an easier process of annotation but also the usage of state-of-the-art image understanding models. These models detect or segment the objects captured with the camera and project the labels to the 3D point clouds captured by the LiDAR system, and by doing so, it either completely does the lidar labeling job or greatly augments it.
Uses of deep learning with LiDAR data
Given the type of output that LiDAR systems generate, combining them with neural networks seems like a natural fit, and indeed neural networks operating on point clouds have proven effective. In 2016, researchers started applying deep neural networks to LiDAR data for simple understanding tasks like classification, and semantic segmentation. Back then, the infamous PointNet built a U-Net like architecture to operate directly on point clouds and demonstrated how it is possible to get superior results than the ones obtained with image-based models.
After laying the foundation, researchers found applications in increasingly complex tasks in the domain, such as instance segmentation, object detection, object completion, pose estimation, etc. Eventually, this progress made it possible to create the very first generative 3D model released by OpenAI in December 2022, called Point-E. To break it down, it is the 3D version of the infamous Dall-E 2 model, although it has significantly worse performance. The reason, as argued by the creators of the model, is the lack of big datasets of 3D models accompanied by text data describing them. They circumvented this problem by generating a 2D image from the text prompt at which they notoriously excel with Dall-E, and then they learn to generate a 3D point cloud corresponding to the image. The authors argue that the results can be significantly improved when a large-scale 3D point cloud dataset with captions is available.
Challenges of neural networks with LiDAR
- An interesting challenge for neural networks operating on LiDAR data is the fact that there's a ton of variation based on scanning times, weather conditions, sensor types, distances, backgrounds, and a plethora of other factors. Because of the way LiDAR works, the density and intensity of objects vary a lot.
- Combined with the fact that sensors are often noisy and LiDAR data, in particular, is often incomplete (because of factors like low surface reflectance of certain materials and cluttered backgrounds in cities), neural networks working with LiDAR data need to be able to handle a lot of variation. Another problem with 3D point data is that, unlike 2D images, there isn't an intuitive order to the points from a LiDAR sensor, which introduces the need for permutation and orientation invariance in our model, which not all architectures satisfy.

Furthermore, these four interesting families of architectures proposed to deal with LiDAR data as follows:
1) Point cloud-based methods: These networks operate directly on the point clouds using different approaches. One such approach is learning the spatial features of each point directly via MLPs and accumulating them via max-pooling.
2) Voxel-based methods: The 3D data is divided into a 3D grid of voxels (essentially a grid of cubes), and 3D convolution and pooling are applied in a CNN-like architecture.
3) Graph-based methods: These methods use the inherent geometry present in point clouds to construct graphs out of them and apply common GNN architectures like graph CNNs and graph attention networks (which also happen to satisfy the earlier mentioned condition of permutation invariance).
4) View-based methods: These methods rely on creating 2D projections of the point clouds using the tried and tested architectures from 2D computer vision. In this case, a tactic that can help improve model performance is to create multiple projections from different angles and vote for a final prediction.
10 most common applications of LiDAR data
Thanks to its ability to provide highly accurate, detailed, and reliable spatial information, LiDAR technology now has a wide range of applications across various industries. Some of the most common LiDAR application use cases include:
- Autonomous vehicles: As we highlighted above, LiDAR sensors are crucial for enabling self-driving cars to sense and understand their surroundings, detect obstacles, and make safe driving decisions. These sensors provide high-resolution, real-time data for object detection, tracking, and classification.
- Robotics and drones: In robotics, LiDAR is used for navigation, obstacle avoidance, and SLAM (Simultaneous Localization and Mapping). Drones equipped with LiDAR can be employed in numerous applications, such as precision agriculture, wildlife monitoring, and infrastructure inspection.
- Precision agriculture and crop monitoring: LiDAR can be utilized in agriculture to assess and monitor crop health, estimate yields, and optimize farm management practices. By generating detailed 3D maps of the fields, LiDAR can provide valuable insights into crop height, density, and biomass. This information can be used to optimize irrigation, fertilization, and pest control strategies. Additionally, LiDAR can help identify areas of water stress or nutrient deficiency, allowing farmers to make targeted interventions and improve overall crop productivity.
- Infrastructure inspection: LiDAR can be used for inspecting and monitoring critical infrastructure such as bridges, roads, railways, power lines, and pipelines. Through its providence of accurate 3D data, LiDAR helps assess structural integrity, identify potential risks, and plan maintenance activities.
- Archeology and cultural heritage: LiDAR can reveal hidden archaeological sites, ancient settlements, and cultural landscapes by penetrating vegetation cover and providing high-resolution, detailed terrain information. This LiDAR technology aids in site discovery, documentation, and preservation efforts.
- Environmental monitoring: LiDAR is used in various environmental applications, including monitoring vegetation growth, habitat mapping, and assessing the health of forests. LiDAR also aids in the study of coastal erosion, glacier monitoring, and climate change research.
- Geology and mining: In geology, LiDAR is used to study geological features, such as fault lines, landslides, and rock formations. In the mining industry, LiDAR is employed for resource exploration, volume calculations, and mine planning and safety.
- Atmospheric research: LiDAR systems can be used to study the Earth's atmosphere by measuring aerosols, clouds, and wind patterns. This information that LiDAR provides is highly valuable for understanding air quality, climate change, and weather forecasting.
- Security and defense: LiDAR is used in various security and defense applications, including border surveillance, area mapping, and target detection. LiDAR can also be used for emergency response and disaster management.
- Mapping and surveying: LiDAR is widely used in topographic mapping, generating highly accurate elevation models, and mapping large areas with greater speed and precision. LiDAR applications include land-use planning, forestry, agriculture, flood modeling, and urban planning.
Annotating LiDAR data
As we know by now, the most common deep learning tasks on LiDAR data are variants of semantic segmentation, object detection, and classification. Therefore, annotating LiDAR data is quite similar to annotating images for those tasks. In the case of object detection, the difference is that here one puts a 3D bounding box instead of a 2D one as in the case of images. As for the semantic segmentation we want to have a single label for each point in the point cloud, as we want a single label for each pixel in an image.
You might think that there's not much of a difference, hence why the LiDAR annotation should be relatively easy as in the case of image datasets. Unfortunately, that's not the case. Because of the 3D nature of the data and the inevitable 2D nature of the editor, the annotator needs to do a tremendous amount of scene navigation and viewing of angle changes in order to correctly label all the points of an object with the same class.
To mitigate these difficulties for annotators, a good amount of engineering effort is needed, which explains the sparsity of available open-source LiDAR annotation tools for point cloud data. Those few that are available support only 3D bounding box annotation, which is relatively easy to implement compared to the semantic segmentation toolset.
For semantic segmentation, selecting points with 3D bounding boxes can get as tedious as labeling points one by one. To this end, one has to implement special tooling that enables them to select a bunch of points at once in a very intuitive manner.
We, at SuperAnnotate, achieve this by introducing a tool in our LiDAR editor very similar to a brush, just in a 3D scenario. When holding the mouse pointer on a point in the point cloud we not only select the point itself but also others that fall in the brush radius currently set. We give the user an opportunity to increase or decrease the size of the brush as much as needed, as different objects or even different parts of objects often need different brush size granularity to efficiently label all the points. Another important aspect to consider is the ability to increase or decrease the point cloud point sizes, as it both visually reduces the sparsity present in the LiDAR data and enables smoother movement of the brush tool through the scene.
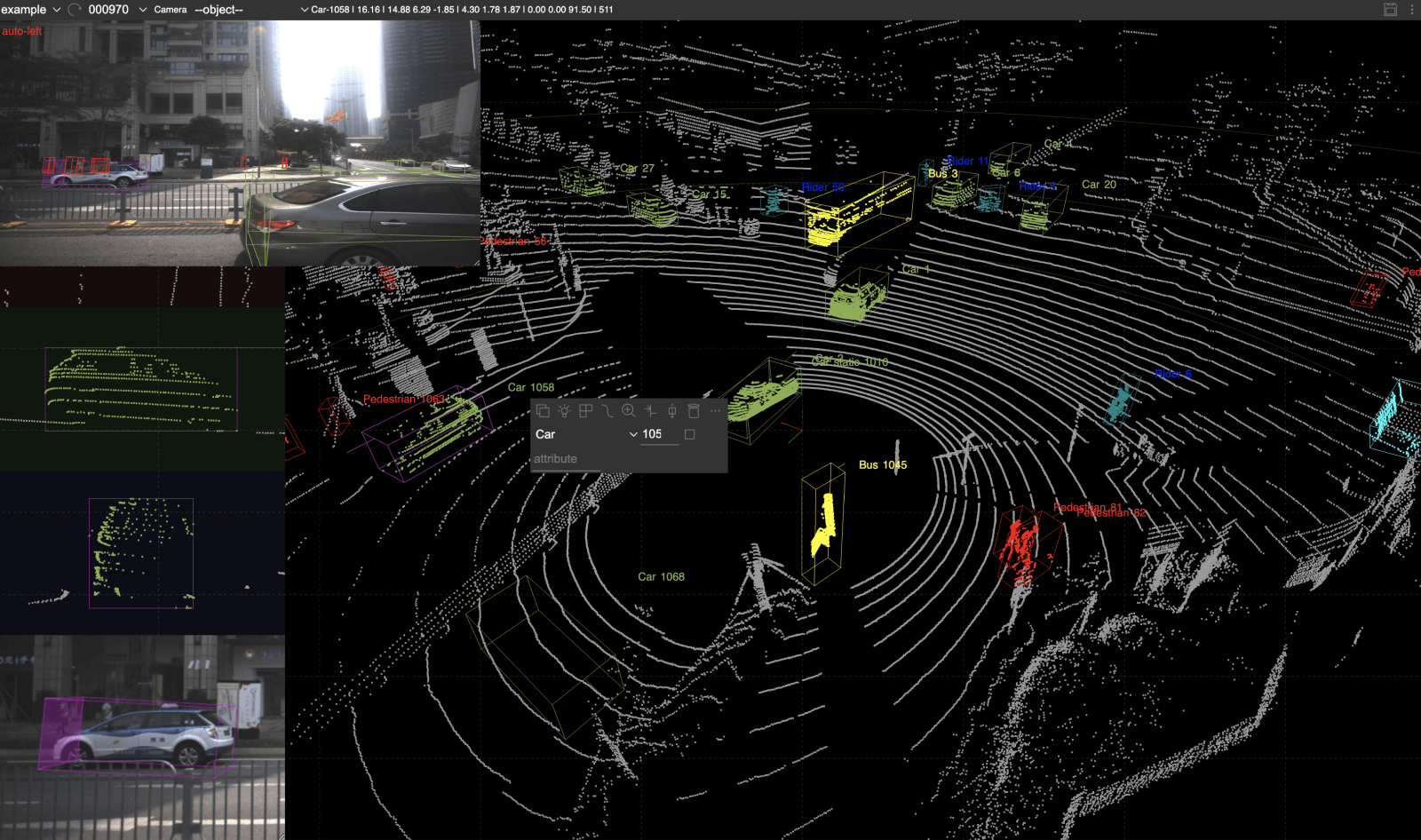
To sum it up, having a good tool is a key component in annotating LiDAR data. In this regard, not only convenient labeling features contribute to the success of the project but also the management capabilities of the tool. As to eventually get high-quality labels for big LiDAR datasets, one should be able to manage a team of specialized annotators by setting up complex workflows with multi-stage quality assurance.
Choosing a LiDAR annotation partner
There are a handful of companies across the world that provide both LiDAR annotation services and are building their own software to support those services. Most companies provide outsourcing services with the tools that the customer has to build in-house. However, such solutions are often non-scalable for creating high-quality training data. The image below summarizes the two sections below and provides detailed components when choosing LiDAR annotation services or software.
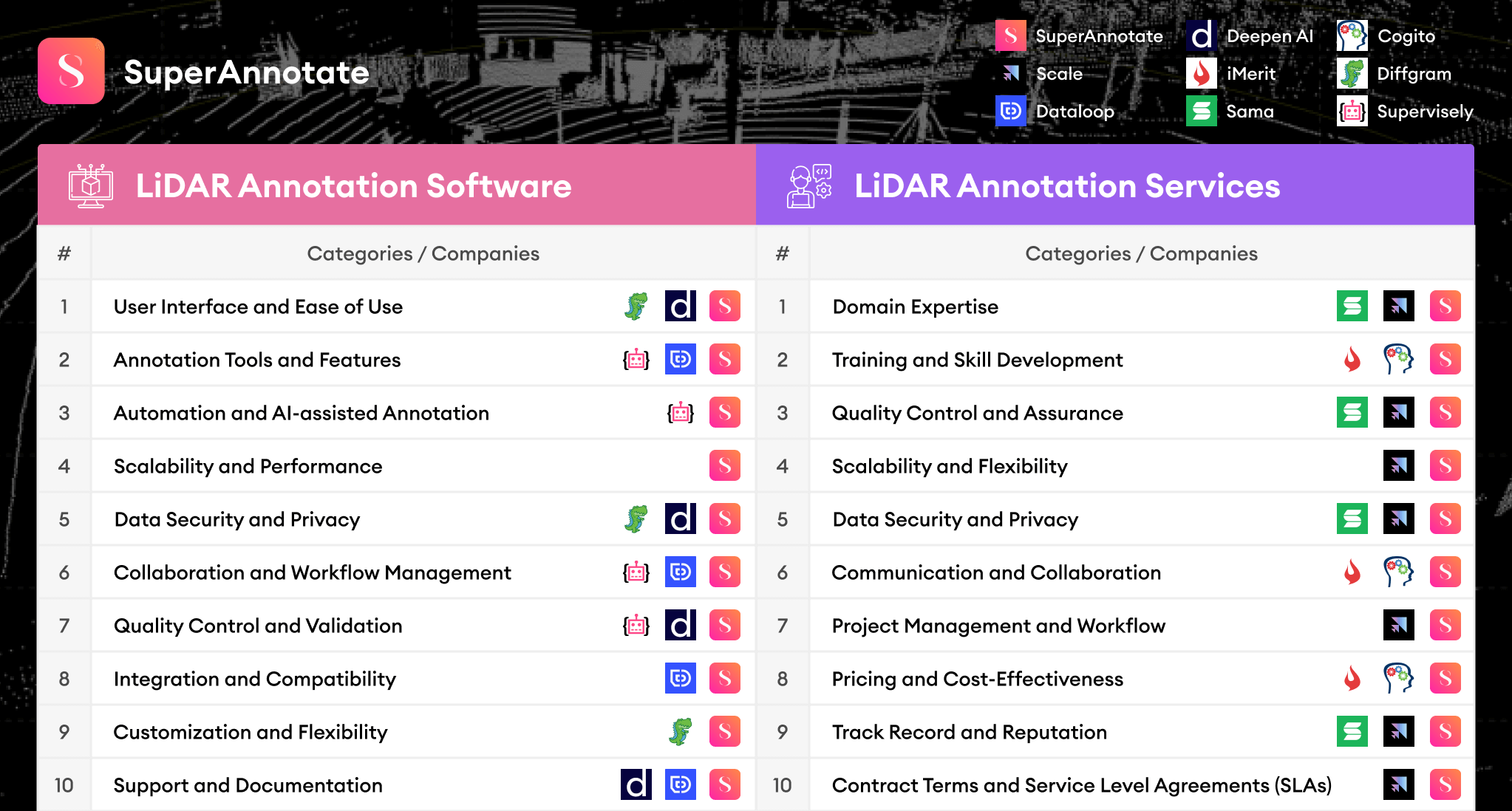
10 things to consider when choosing LiDAR annotation software
When selecting a LiDAR annotation software, there are several important factors to consider to ensure the software meets your needs and provides high-quality annotations for your specific application. Some of the most important aspects to consider include:
- User interface and ease of use: The software should have an intuitive and user-friendly interface that allows annotators to efficiently navigate through the features and tools. A steep learning curve could hinder productivity and increase the time needed for annotators to become proficient in using the software.
- Annotation tools and features: The software should provide a comprehensive set of annotation tools tailored to LiDAR data, such as bounding boxes, segmentation, and point cloud labeling. The tools should allow for efficient and precise annotation of objects and features in the 3D point cloud data.
- Automation and AI-assisted annotation: To improve annotation speed and efficiency, the software should offer automation features or AI-assisted annotation tools. These can help streamline the annotation process by automatically suggesting labels, object boundaries, or segmentations, which can then be fine-tuned by the annotator.
- Scalability and performance: The software should be capable of handling large datasets and scaling to accommodate the increasing data volumes associated with LiDAR projects. It should be able to process and display large point clouds without significant performance issues or crashes.
- Data security and privacy: The software should provide robust data security and privacy features, especially if you are working with sensitive or proprietary data. This includes encryption, access controls, and secure storage of the annotated data.
- Collaboration and workflow management: You need to look for features that support collaboration among annotators and project managers, such as task assignment, progress tracking, and communication tools. This can help streamline the annotation process and ensure consistency across the team.
- Quality Control and Validation: The software should offer quality control and validation tools to ensure the accuracy and consistency of the annotated data. This may include features like automated error detection, auditing tools, and built-in metrics to assess the quality of the annotations.
- Integration and Compatibility: The LiDAR annotation software should be compatible with your existing tools, hardware, and software platforms. It should offer APIs or integration options to easily connect with your data storage, machine learning frameworks, or other relevant systems.
- Customization and Flexibility: The software should be adaptable to your specific requirements, allowing for the customization of annotation tools, labels, or workflows. This flexibility will enable you to tailor the software to your project's unique needs.
- Support and Documentation: Choose a software provider that offers responsive customer support and comprehensive documentation to help you troubleshoot issues, learn about new features, and get the most out of the software.
10 things to consider when choosing LiDAR annotation services
Similar to the software, when outsourcing LiDAR annotation tasks to an external workforce, there are several essential components to consider to ensure the success of your LiDAR project and the quality of the annotated data:
- Domain expertise: The workforce should have experience and expertise in LiDAR annotation and be familiar with the specific application and industry requirements. This expertise ensures that the annotations are accurate, consistent, and relevant to your project.
- Training and skill development: The outsourcing partner should invest in training and skill development for their annotators. This includes providing resources, guidelines, and ongoing support to ensure annotators can efficiently and accurately perform their tasks.
- Quality control and assurance: The workforce should have a robust quality control and assurance process in place to maintain the accuracy and consistency of the annotations. This may include regular audits, error detection mechanisms, and feedback loops to continually improve the annotation quality.
- Scalability and flexibility: The outsourcing workforce should be able to scale up or down according to your project's needs and timelines. This allows you to adjust the annotation capacity as your data volumes or project requirements change.
- Data security and privacy: The workforce should adhere to strict data security and privacy protocols to protect sensitive or proprietary data. This includes secure data storage and transfer, access controls, and compliance with relevant data protection regulations.
- Communication and collaboration: Choose an outsourcing partner that offers clear and open lines of communication, enabling you to stay informed about the progress of your project, provide feedback, and address any concerns that may arise.
- Project management and workflow: The workforce should have a well-defined project management and workflow process, ensuring that tasks are efficiently assigned, completed, and reviewed. This helps to streamline the annotation process, maintain consistency, and meet deadlines.
- Pricing and cost-effectiveness: The outsourcing workforce should offer competitive and transparent pricing, providing a cost-effective solution for your LiDAR annotation needs. Consider factors like per-annotation pricing, project-based pricing, or hourly rates when evaluating the cost-effectiveness of the workforce.
- Track record and reputation: Consider the outsourcing partner's track record, reputation, and client testimonials. This can give you insights into the quality of their work, their ability to meet deadlines, and their overall reliability.
- Contract terms and service level agreements (SLAs): Ensure that the outsourcing partner provides clear contract terms and service level agreements that outline the project's scope, timelines, and deliverables. This helps set clear expectations and ensures accountability on both sides.
Final thoughts
As we discussed, a LiDAR instrument uses laser light combined with sensors that catch the reflected light to construct the LiDAR data that sparsely represent the 3D surrounding environment. The LiDAR data is used in various technologies - smartphones, autonomous vehicles, airborne systems, etc. It does not stop here, for more new applications will be found gradually as the LiDAR data becomes abundant, despite the mentioned difficulties in collection and labeling processes.
Considering all the points mentioned above, it can be difficult to find a combination of software and services that ticks all the boxes — this is where we at SuperAnnotate step in to offer an all-in-one solution for all your LiDAR data needs. Whether it is flexibility, quality control, and ease of use, when choosing to work with SuperAnnotate, we cover it all.
We think that the LiDAR data annotation tools existing in the market currently are yet at a very early stage. Most of them don't have any smart features integrated that use the power of machine learning or deep learning models. Similar to the image tools, we envision them having smart prediction and interactive segmentation models that would operate directly on the point cloud data. There can also be LiDAR data-specific smart tools, such as ground point removal (mostly used in object detection tasks) or tracking objects across the frames of a LiDAR scene. And finally, let's end on a strong note, by stressing on SuperData and how it will offer high-quality data, which in its turn will enhance the models behind those smart features even further!