


Object detection is a pivotal aspect of computer vision that involves identifying and locating specific objects within an image or video frame. Unlike image classification tasks, assigning a singular label to an entire image, object detection algorithms discern multiple objects in an image and assign each a bounding box, indicating its position within the input image.
This task is typically powered by deep learning models such as convolutional neural networks (CNNs), which are trained on vast datasets to recognize patterns and features of different objects. Object detection algorithms have diverse applications ranging from self-driving cars, where it's crucial to detect other vehicles or pedestrians, to retail, where it can automatically track products on shelves.
Over the years, numerous algorithms like R-CNN, SSD, and YOLO have been developed to optimize accuracy and inference speed, making object detection a dynamic and rapidly evolving field in computer vision.

Importance of real-time object detection
Real-time object detection elevates the capabilities of computer vision by enabling instantaneous recognition and localization of objects within a dynamic environment. The essence of "real-time" lies in processing images or video frames as they arrive, typically at a rate of several frames per second, without noticeable delays.
This immediacy is critical in applications where split-second decisions are paramount. For instance, in autonomous vehicles, the ability to detect and react to obstacles, traffic signals, or pedestrians in real time can be the difference between safe navigation and potential accidents.
Similarly, in security and surveillance, real-time detection can trigger immediate alerts for suspicious activities, enhancing safety measures. Moreover, augmented reality (AR) applications rely on it to seamlessly overlay digital information on the physical world. As technological advancements continue, the demand for real-time object detection is expected to grow, underlining its significance in shaping a responsive and interactive digital future.

Introduction to the YOLO algorithm (You Only Look Once) and its significance in the field
The YOLO algorithm, which stands for "You Only Look Once," revolutionized the realm of object detection with its distinctive approach. Unlike traditional methods involving multiple stages, such as region proposals followed by classification, YOLO accomplishes detection in a single forward pass of the network. By dividing an input image into a grid and predicting multiple bounding boxes and class probabilities simultaneously for each grid cell, the YOLO algorithm offers both speed and accuracy.

This unified architecture allows it to process images remarkably fast, making it particularly suited for real-time applications. Since its inception, several versions of the YOLO model have been released, each refining its performance and architecture. Its efficiency in balancing speed and accuracy underscores YOLO's significance in the field.
Pre-YOLO era: A glimpse into traditional object detection
Before the advent of YOLO, object detection predominantly relied on methods such as the sliding window and region proposal techniques. The sliding window approach involved scanning the entire image with varying-sized windows to detect objects at different scales and locations. This method, although comprehensive, was computationally intensive as it required evaluating numerous windows across the input image.
On the other hand, region proposal techniques, as seen in methods like R-CNN, first identified regions of interest that likely contained objects and then classified each proposed region. While this reduced the number of evaluations compared to the sliding window, it still consisted of a two-step process that could be slow and computationally demanding.

{kind=link}
Both these strategies faced challenges in terms of speed, especially when applied to high-resolution images or real-time video streams. Furthermore, striking a balance between accuracy and computational efficiency was a constant struggle. The need for faster and more efficient algorithms that didn't compromise on accuracy paved the way for breakthroughs like the YOLO model, which addressed many of these pre-existing challenges.
The birth of YOLO: Simultaneous bounding boxes classification and regression problem
The emergence of YOLO marked a transformative moment in the landscape of object detection. Breaking away from traditional paradigms, YOLO introduced a novel methodology underpinned by a few core principles. Firstly, YOLO's expansion, "You Only Look Once," encapsulates its foundational idea: object detection should occur in a single forward pass through the neural network. This sharply contrasts with methods that separate object localization and classification into distinct stages.
YOLO's strategy divides an image into a grid, and for each grid cell, it predicts multiple bounding boxes and their associated class probabilities simultaneously. This unified framework drastically reduces computational overhead, making real-time detection feasible without sacrificing accuracy.
Compared to previous methods, YOLO's streamlined approach offers significant advantages. It reduces latency, making it apt for real-time applications, and its holistic view of the image ensures contextual understanding, reducing false positives. With YOLO's inception, the field witnessed a paradigm shift, emphasizing both efficiency and accuracy in object detection.
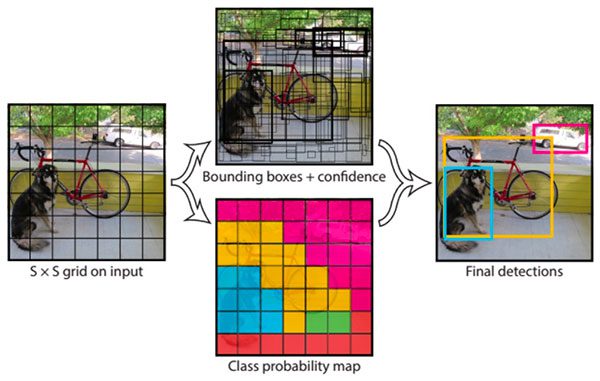
YOLO v1: The first version
YOLO v1 burst onto the computer vision scene and introduced a fresh perspective on object detection. Its architecture was distinct; the model split images into a 7x7 grid, and for each grid cell, predicted bounding boxes along with class probabilities, ultimately producing a fixed number of predictions. This was inherently different from the iterative proposals and classifications of prior methods.

{kind=link}
Performance-wise, YOLO v1 outstripped many contemporaneous algorithms in terms of speed, making real-time detection not just a theoretical aspiration but a tangible reality. However, its first iteration had limitations. Detecting smaller objects proved challenging for YOLO v1, as its design was more inclined towards identifying larger, more prominent objects.
Additionally, the model demonstrated sensitivity to the positioning of objects. If an object straddled multiple grid cells, the model occasionally faltered in its predictions. Despite these initial shortcomings, YOLO v1 laid a robust foundation, setting the stage for subsequent refinements and iterations that would further refine the YOLO model and elevate its capabilities.
YOLO v2 (YOLO9000): Improvements and innovations
YOLO v2 model suggested several improvements on top of the v1 architecture, such as multi-scale training, anchor boxes, and the Darknet-19 architecture.
Multi-scale training
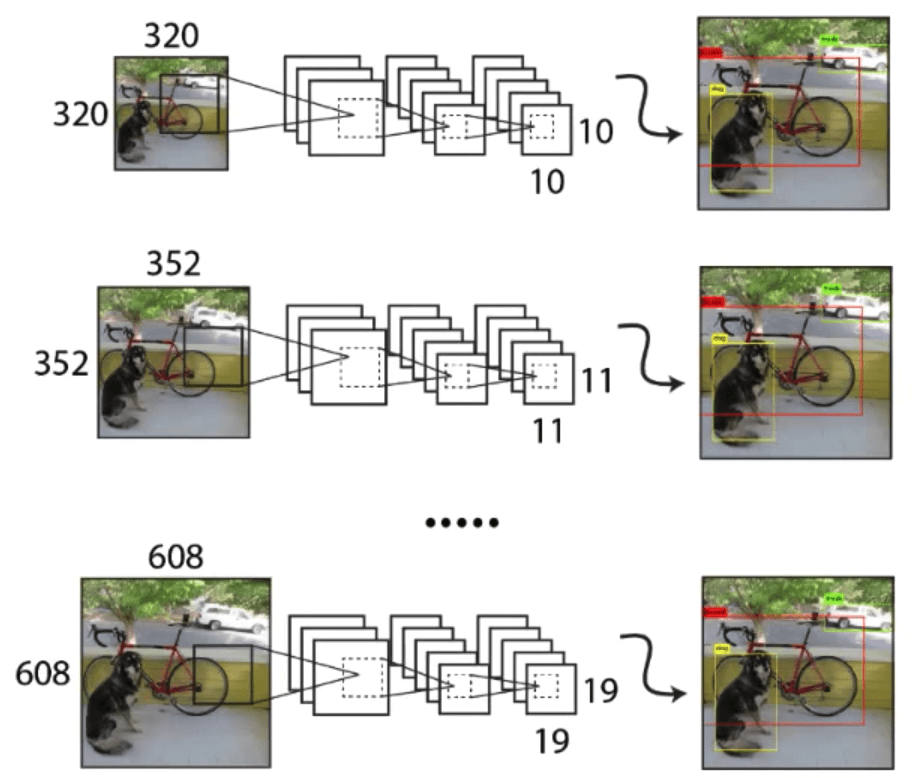
YOLO v2, often referred to as "YOLO9000" due to its ability to detect over 9000 object classes, introduced several refinements to address the shortcomings of its predecessor. One of the most significant enhancements was the concept of multi-scale training. Recognizing that objects in real-world images appear at various scales and sizes, the YOLO v2 model was trained to predict objects across different scales.
In practical terms, during the training process, the size of the input images was periodically changed. For instance, the network might be trained on images of size 320x320 for a certain number of batches, and then the resolution would be increased to, say, 416x416 for the subsequent ones. This process continued for even larger resolutions. This dynamic adjustment enabled the model to better adapt to objects of varying dimensions.

{kind=link}
This approach has two benefits. Firstly, it significantly improved the model's ability to detect smaller objects, a challenge that YOLO v1 faced. Secondly, it endowed the model with a more generalized understanding of object scales, making it more robust and versatile across diverse real-world scenarios. This multi-scale training strategy was a key factor in the improved performance and versatility of YOLO v2 over the original version.
Anchor boxes
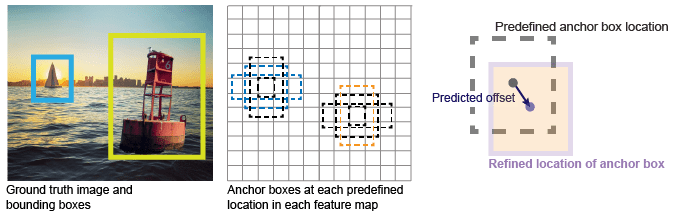
Another groundbreaking enhancement in YOLO v2 was the introduction of anchor boxes. Recognizing that objects in images come in various shapes and aspect ratios, the anchor box concept aimed to improve the bounding box coordinates prediction mechanism.

{kind=link}
Predicting small bounding boxes from scratch can be challenging in traditional object detection approaches. Anchor boxes, however, provide predefined bounding box coordinates, fixed aspect ratios, and sizes based on common shapes found in the training dataset. During the prediction phase, the model adjusts these anchor boxes to better fit the actual bounding boxes of the objects in the image.
The idea is that it's easier for the model to predict adjustments to these predefined bounding boxes than to generate accurate bounding boxes from scratch. For example, if a dataset frequently contains tall, rectangular objects (like standing humans), one of the anchor boxes might have a tall, thin shape. During detection, the model can use this anchor box as a starting point and make adjustments to fit each detected person better.
Incorporating anchor boxes was pivotal in addressing overlapping objects and improving recall, especially for objects that might have been challenging due to their aspect ratios or sizes. By utilizing anchor boxes, YOLO v2 demonstrated a more refined bounding box prediction, enhancing its detection accuracy and making it even more competitive in the object detection landscape.
Darknet-19
Darknet-19 is the underlying neural network architecture that YOLO v2, or YOLO9000, utilizes for its object detection tasks. It's a custom-built architecture designed to be fast and efficient, which is why it's particularly well-suited for real-time applications.

Here are some key features of the Darknet-19 architecture:
Layers
Darknet-19 comprises 19 convolutional layers accompanied by five max-pooling layers. The name "Darkneet-19" originates from these 19 convolutional layers.
Convolutional Layers
These layers make use of 3x3 filters primarily, which helps in retaining fine-grained features. Some of the later layers in the architecture use 1x1 filters for dimension reduction.
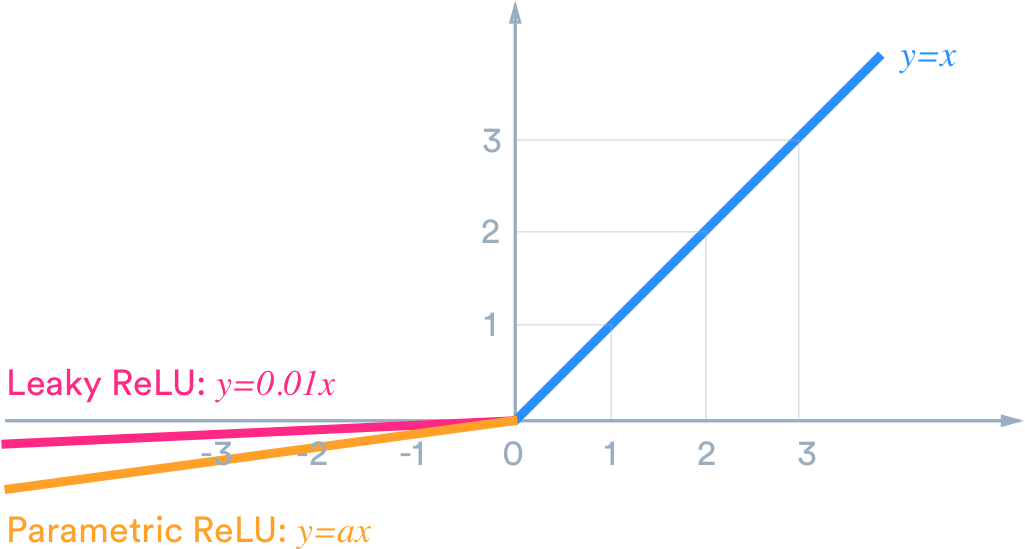
Activation Functions

{kind=link}
Each convolutional layer is followed by a non-linear activation function - Leaky ReLU (Rectified Linear Unit), which helps add non-linearity to the model without significant computational overhead.
Normalization
Darknet-19 incorporates batch normalization after its convolutional layers. This aids in stabilizing training, reducing the need for meticulous initialization, and somewhat mitigating the effects of overfitting.
Global average pooling

{kind=link}
At the end of the network, before the final softmax layer, global average pooling is used. This replaces the fully connected layers commonly seen in other architectures, leading to a reduction in the overall number of parameters and, consequently, less risk of overfitting.
The choice of Darknet-19 for YOLO v2 wasn't arbitrary. Its design is a testament to the requirement of having a high-performing yet computationally efficient neural network for real-time object detection, perfectly aligning with the objectives of the YOLO series.
YOLO v3: Aiming for balance
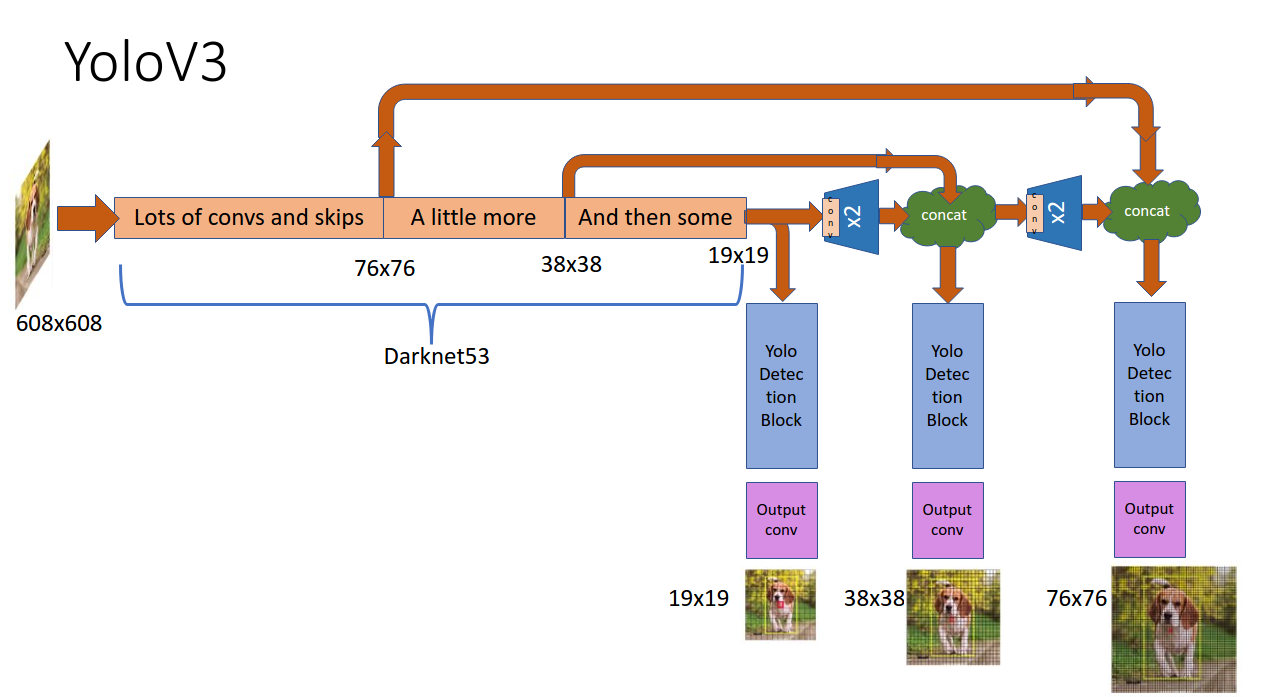
As object detection continued to evolve, the need for a model that strikes a harmonious balance between detection speed and accuracy became paramount. YOLO v3, the third iteration of the renowned YOLO series, emerged as an answer to this call. While retaining the foundational principles of its predecessors, YOLO v3 introduces enhancements and refinements, fine-tuning its performance across varying object sizes and ensuring a more holistic detection capability. In this section, we delve into the intricacies of YOLO v3, exploring its architectural advancements and understanding its drive toward achieving a balanced object detection model.

{kind=link}
Modifications in architecture
YOLO v3 brought about several architectural modifications to further refine object detection capabilities. Here's a breakdown of these changes:
Darker architecture
YOLO v3 uses a deeper architecture named "Darknet-53", which combines the best of Darknet-19 (used in YOLO v2) and some of the residual connections from the ResNet architecture. This resulted in 53 convolutional layers, hence the name. These layers provide a richer feature set for detection while the residual connections assist in training the deeper network.
Three scales for detection
Instead of a single scale, YOLO v3 makes detections at three different scales. This is accomplished using three different sizes of anchor boxes for each scale, thus effectively addressing the issue of detecting objects of varying sizes.
Use of three YOLO layers
To be aligned with the three scales, YOLO v3 introduces three YOLO layers in its network. Each layer is responsible for detecting objects at a particular scale, ensuring a more robust multi-scale object detection.
Bounding box prediction
Instead of using the width and height directly for predicting bounding boxes, YOLO v3 uses a logarithmic space to predict bounding box sizes. This aids in improving accuracy, especially for larger objects.
Class prediction
Instead of using a softmax layer for class prediction (as in YOLO v2), YOLO v3 employs independent logistic classifiers. This allows the model to predict multiple object classes for the same bounding box, making it capable of handling overlapping objects of different classes.
Improved loss function
The loss function was modified to better balance the trade-off between localization errors of bounding box coordinates and classification errors (correct object category identification).
Use of upsampling

{kind=link}
YOLO v3 uses upsampling layers to merge features from previous layers, providing a richer feature set for detection at different scales. This is especially beneficial for detecting smaller objects.
In essence, the architectural modifications in YOLO v3 were focused on enhancing the model's precision without compromising its speed. The shift towards multi-scale detection, combined with the deeper and richer Darknet-53 backbone, allowed YOLO v3 to achieve a commendable balance between performance and accuracy in object detection tasks.
YOLO v3 And SOTA models
During its release, YOLO v3 was juxtaposed against several state-of-the-art models to benchmark its performance. Here's a comparative analysis:
Speed vs. accuracy trade-off
One of the most distinct attributes of YOLO v3 was its ability to maintain a compelling balance between speed and accuracy. While models like Faster R-CNN and RetinaNet might have achieved slightly superior accuracy on certain benchmarks, they typically did so at the cost of computational speed. YOLO v3, on the other hand, retained commendable accuracy while operating at real-time or near-real-time speeds, a balance many models struggled with.
Detection across scales
With its multi-scale detection, YOLO v3 showcased improved performance in detecting smaller objects compared to its predecessor, YOLO v2. However, models like SSD (single shot multibox detector) and some configurations of RetinaNet, which also incorporated multi-scale detection, were competitive in this regard.
Generalization
YOLO v3's architecture, especially with the Darknet-53 backbone and the use of logistic classifiers for class prediction, provided it with a better generalization capability. This meant that YOLO v3 was more adept at handling varied real-world scenarios than some models, which might have been overly optimized for specific benchmark test data.
Limitations
Like any model, YOLO v3 had its challenges. For instance, densely packed objects or objects with overlapping bounding boxes sometimes pose detection challenges. Some other models, especially those optimized for higher average precision (AP) at the cost of speed, might outperform YOLO v3 in such intricate scenarios.
Versatility
The design philosophy behind YOLO always emphasized broad applicability – a model that can detect thousands of object types in varied environments. In benchmarks that evaluated this versatility, such as detecting uncommon object types, YOLO v3 often outshone models that were narrowly optimized for specific, common object categories.
In summary, while other state-of-the-art models of the time might have excelled in specific niches or under certain conditions, YOLO v3 was celebrated for its all-roundedness. It provided a unique combination of speed, accuracy, and versatility, making it a preferred choice for various real-world applications, from surveillance systems to autonomous vehicles.
YOLO v4: The quest for efficiency
As the relentless march of innovation in object detection progressed, the YOLO series presented its fourth iteration, YOLO v4, with a clear objective: achieving unparalleled efficiency. While the preceding versions had set benchmarks in balancing speed and accuracy, YOLO v4 sought to redefine these boundaries, optimizing both computational efficiency and performance of bounding box detection. This version embodies the culmination of learnings from past iterations and integrates novel techniques from contemporary research. In this section, we'll unravel the intricate advancements of YOLO v4 and explore how it raised the bar in the domain of efficient object detection.
Focus on efficiency and scalability
YOLO v4's design ethos is deeply rooted in efficiency and scalability, ensuring that the model not only achieves state-of-the-art detection performance but is also optimized for deployment in various scenarios, ranging from high-end servers to edge devices.
Optimized backbones
YOLO v4 leverages the CSPDarknet53 architecture, which, as previously discussed, provides an efficient gradient flow. This design choice optimizes the model's training process, ensuring a more rapid convergence while demanding fewer computational resources than other sophisticated backbones.
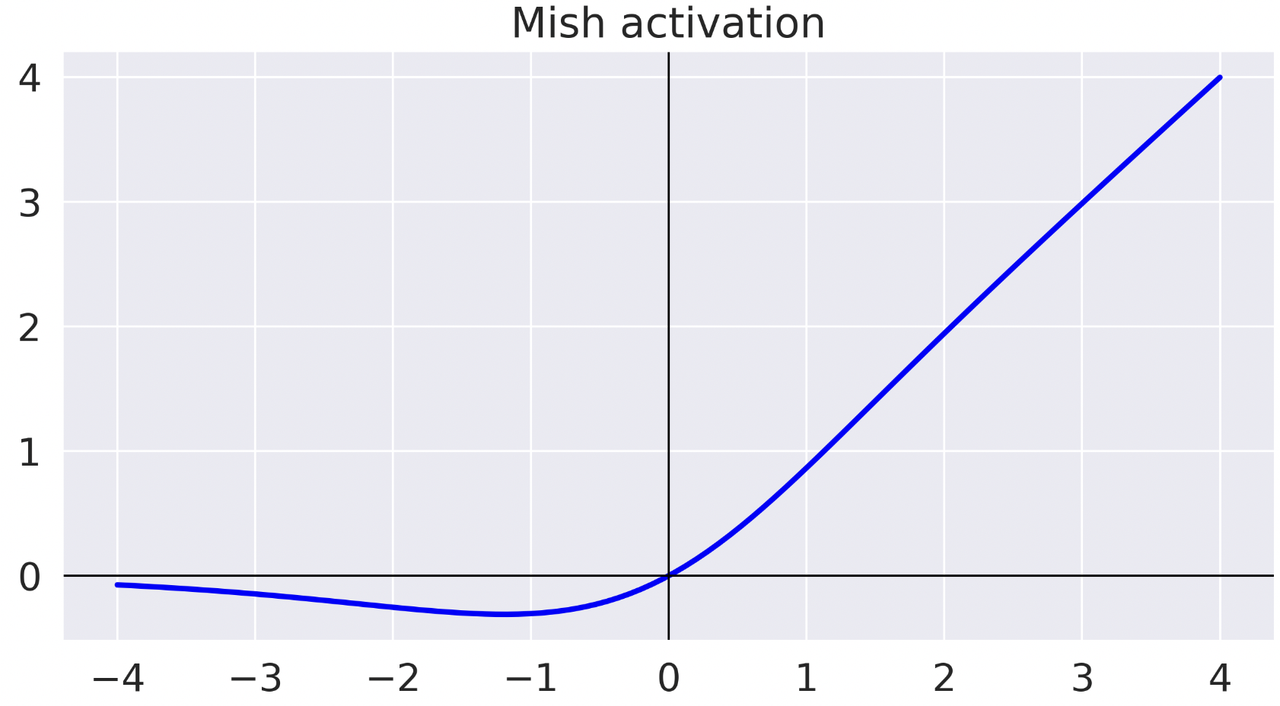
Mish activation function

{kind=link}
YOLO v4 introduces the mish activation function, which has been shown to yield better performance than traditional activation functions like ReLU while maintaining a comparable computational cost.
CIOU Loss

The use of the complete intersection over union (CIOU) loss aids in better bounding box regression, leading to more precise object localization without significantly increasing computational demands.
Modularity and scalability
One of the core strengths of YOLO v4 lies in its modular design. Various components, like PANet or SAM block, can be added or removed based on the computational budget and the application’s specific requirements. This makes YOLO v4 highly scalable – a critical feature when deploying the model on devices with varying computational capacities.
Advanced data augmentation

{kind=link}
YOLO v4 integrates advanced data augmentation techniques like Mosaic augmentation and CutMix. These techniques not only improve detection performance but also enhance the model's robustness. A more robust model can be deployed in diverse real-world scenarios without the need for excessive fine-tuning, which is a boon for efficiency.
Attention mechanisms
By focusing on relevant parts of the image through mechanisms like the SAM block, YOLO v4 ensures that computational resources are spent on regions of importance. This selective attention translates to more efficient processing, especially in cluttered or diverse scenes.
Neck and head optimizations
The "neck" of the architecture, which bridges the backbone and the final detection layers (or "head"), is designed to merge features across different scales efficiently. The detection head is fine-tuned for speed, with optimizations ensuring rapid and accurate bounding box and class predictions.
In essence, every layer and component in YOLO v4 is meticulously designed or chosen to push the boundaries of efficiency. Whether it's the choice of backbone, the activation functions, or the attention mechanisms, the model consistently strives for a balance between performance and computational cost, making it one of the most efficient and scalable object detectors of its time.
Innovations in YOLO v4: CSPDarknet53, PANet, and SAM Block
YOLO v4 introduced a series of architectural and methodological advancements to refine its object detection capabilities further. Among these, CSPDarknet53, PANet, and the SAM block stand out as key components that significantly bolstered its performance.
CSPDarknet53

The "CSP" in CSPDarknet53 stands for "Cross Stage Hierarchical Networks." This technique divides the feature map into two parts and then merges them during the latter stages. Such partitioning and cross-stage hierarchy improve gradient flow, which can enhance learning, especially in deeper networks.
By integrating the CSPNet strategy with the Darknet53 architecture (which was pivotal in YOLO v3), CSPDarknet53 was born. This new backbone provides enhanced performance with fewer computations, achieving the goal of improved efficiency.
PANet (Path Aggregation Network)

PANet enhances the feature hierarchy of the network. It allows for the upward path (where semantically stronger, lower-resolution features are present) to propagate to the downward path (where higher-resolution, less semantically strong features exist).
By leveraging PANet, YOLO v4 achieves better object localization, especially for smaller objects. This architecture ensures that rich feature information is available across scales, providing a comprehensive multi-scale detection capability.
SAM Block (Spatial Attention Module)

{kind=link}
The SAM block helps the network focus on the relevant spatial regions of the feature map. It introduces spatial attention to the features, emphasizing areas that are more likely to contain meaningful information about the object.
By integrating spatial attention, the network can make more accurate decisions about object locations and sizes. This not only improves detection accuracy but also aids in the precise delineation of object boundaries.
Collectively, these three key components – CSPDarknet53 for an efficient and robust feature extraction backbone, PANet for improved hierarchical feature utilization across scales, and the SAM block for sharp spatial attention – endow YOLO v4 with a formidable capability to detect objects with high precision, all while maintaining an edge in computational efficiency. This synergy of methodologies pushes YOLO v4 closer to the ideal intersection of speed and accuracy in the object detection landscape.
CIOU loss for better bounding box prediction
Accurate bounding box prediction is paramount in object detection, as it determines how precisely an object's location and shape are delineated. Traditionally, models employed metrics like intersection over union (IoU) to measure the overlap between the predicted bounding box and the ground truth box. However, relying solely on IoU can lead to certain challenges, particularly in handling overlapping bounding boxes, different bounding box sizes, or bounding boxes that don't overlap at all. To address these nuances, YOLO v4 incorporates the complete intersection over union (CIOU) loss, significantly improving bounding box prediction.
Basics of CIOU
The CIOU loss is an advanced version of the standard IoU loss, which considers not just the overlap between bounding boxes but also the distance between the central points of the two bounding boxes, predicted and ground truth, as well as the aspect ratio.
Central point distance
One of the components of the CIOU loss calculates the distance between the centers of the predicted bounding box and the ground truth. By incorporating this distance into the loss, the model is penalized for boxes that might have a high IoU but aren’t perfectly aligned regarding object center points. This ensures better alignment of detected objects.
Aspect ratio consistency
Another component of the CIOU loss takes into account the aspect ratio, ensuring that the predicted bounding boxes not only overlap well with the ground truth bounding boxes but also maintain a consistent shape. This is particularly important for objects with distinct elongated or irregular shapes.
Advantages over standard IoU
By accounting for these additional geometric factors, CIOU provides a more holistic measure of bounding box prediction quality. In scenarios where two bounding boxes might have the same IoU value, CIOU can differentiate between them based on their center alignment and aspect ratio consistency, leading to more accurate and consistent predictions.
Impact on training
Integrating CIOU loss into the training process of YOLO v4 has been shown to speed up the convergence, as the model receives more comprehensive feedback on its predictions. Faster convergence can reduce training times and resources, further emphasizing the model's focus on efficiency.
YOLO v5: Streamlined for production
With the continuous evolution of the YOLO series, YOLO v5 emerges as a testament to the pursuit of perfection in the object detection model, designed with a keen focus on production-ready deployments. This iteration prioritizes not only top-notch detection capabilities but also the practicalities of integration into real-world applications. By emphasizing factors like model size, inference speed, and adaptability, YOLO v5 bridges the gap between high-performance object detection and seamless implementation in diverse environments. In this section, we will delve into the intricacies of YOLO v5 and explore how it stands out as a model truly streamlined for production scenarios.
Architecture simplifications
In its quest to become more production-friendly, YOLO v5 introduced various architectural simplifications that made the model leaner without compromising its detection prowess. These modifications ensured faster inference times, ease of deployment, and efficient adaptability across diverse platforms. Let's discuss some of these key architectural changes:
- Reduced complexity: One of the most noticeable shifts in YOLO v5 was the reduction in the model's overall complexity. By removing or refining certain layers and components that contributed less to performance, YOLO v5 achieved a balance between model size and detection accuracy.
- Optimized backbone: The backbone, responsible for feature extraction, underwent optimizations to ensure faster processing and reduced computational requirements. This led to quicker initial feature maps that maintained a rich input data representation.
- Streamlined neck and head: The components connecting the backbone to the final output layers (often referred to as the 'neck') and the detection layers (the 'head') were streamlined. This resulted in a more efficient flow of information and faster object detection and classification processes.
- Focus on edge deployment: With a growing emphasis on edge computing, YOLO v5's architecture was tailored to cater to devices with constrained computational resources. This meant optimizations that allowed for real-time inference, even on devices like smartphones or low-powered cameras.
- Modularity: After recognizing the diverse needs of different applications, YOLO v5's architecture was designed to be modular. This enables developers to easily add or remove components based on specific requirements, ensuring the model remains versatile across different deployment scenarios.
- Efficient activations and operations: YOLO v5 incorporated activation functions and operations, which are computationally efficient and maintain high performance. This fine-tuning at the operation level ensured that each model part contributed effectively to the overall speed and accuracy.
- Reduced redundancy: Any redundancies in the architecture, such as repetitive layers or operations that contributed minimally to the overall performance, were identified and eliminated or refined. This further contributed to the model's lean nature.
In essence, YOLO v5's architectural simplifications can be seen as a meticulous exercise in efficiency. Each change, whether major or minor, was driven by the objective of creating a powerful model in its detection capabilities and primed for real-world, production-level deployments across a spectrum of devices and applications.
Emphasis on deployment and ease of use
YOLO v5, recognizing the critical need to transition from research environments to real-world applications, placed a significant emphasis on deployment readiness and user-friendliness. This shift was crucial to ensure that YOLO's powerful object detection capabilities were accessible and straightforward to implement across various platforms and scenarios. Here's a deeper look into YOLO v5's approach to deployment and ease of use:
- Pre-trained models: YOLO v5 offered a suite of pre-trained models tailored to various computational budgets. From lightweight models suitable for mobile deployments to more robust versions for server-side processing, users could pick a model best suited for their specific use case.
- Tool integration: YOLO v5 emphasized compatibility with popular machine learning deployment tools, ensuring that integration into existing pipelines, whether on cloud platforms or edge devices, was smooth and hassle-free.
- Customization capabilities: After recognizing the diversity of deployment scenarios, YOLO v5 was designed to be easily customizable. This allowed developers to fine-tune the model for specific applications, ensuring optimal performance in niche environments.
- Streamlined training: For those looking to train the model on custom datasets, YOLO v5 offered an intuitive and efficient training process. This made it easier for organizations to adapt the model to their specific data and requirements.
- Robustness to varied inputs: Designed with real-world variability in mind, YOLO v5 showcased resilience to a range of input data, from low-light images to varying resolutions. This robustness made it a reliable choice for diverse deployment scenarios.
- Feedback loop integration: Acknowledging the dynamic nature of real-world applications, YOLO v5 incorporated mechanisms to easily integrate feedback loops. This allowed continuous improvement of the model based on real-world detections and adaptations.
YOLO v5's commitment to deployment and ease of use highlighted a pragmatic approach, bridging the gap between cutting-edge research and tangible real-world applications. By ensuring that the model was not only powerful but also accessible and easy to integrate, YOLO v5 paved the way for widespread adoption across a myriad of industries and use cases.
Performance in real-world applications
While benchmarks and controlled evaluations provide valuable insights into a model's capabilities, the actual test for any object detection system like YOLO v5 lies in its performance in real-world scenarios. With a plethora of challenges, from varied lighting conditions to unpredictable object orientations, the real world is the ultimate proving ground. YOLO v5, with its tailored design, showcased notable prowess across diverse applications. Let's delve into its real-world performance highlights:
- Retail and inventory management: In retail environments, where object variability is high and timely inventory management is critical, YOLO v5 demonstrated precise detection capabilities. It could accurately identify and count products on shelves, aiding in stock monitoring and automated restocking processes.

- Surveillance and security: In surveillance scenarios, quickly detecting anomalies or intrusions is paramount. YOLO v5's real-time processing capability and high accuracy made it a top choice for security applications, ensuring prompt alerts and responses.

- Agriculture and farming: In agricultural settings, detecting pests and diseases or estimating crop yields is essential. YOLO v5's adaptability ensured accurate detections in such environments, providing farmers with valuable insights to optimize their yield and reduce losses.

- Traffic and urban planning: In urban landscapes, YOLO v5 was employed to monitor traffic patterns, detect traffic violations, and analyze pedestrian movements. Its robustness to varying lighting and weather conditions ensured reliable performance around the clock.

- Industrial automation: In factories and manufacturing units, YOLO v5 facilitated automated quality checks, detecting defects or misalignments on assembly lines in real time, ensuring high production standards and reduced manual interventions.

- Sports analytics: In sports broadcasts, YOLO v5 was employed to track player movements and ball trajectories, and analyze game strategies, enhancing the viewing experience and providing teams with tactical insights.

- Augmented reality (AR) and gaming: In AR applications and gaming environments, where real-time object detection melds virtual and real worlds, YOLO v5's speed and accuracy enriched user experiences, enabling more immersive interactions.

YOLO v5's performance in real-world applications underscored its holistic design philosophy. It wasn't just about achieving high scores in controlled tests but about delivering consistent, reliable, and valuable results in varied and often challenging real-world environments, affirming its stature as a leading object detection solution.
Recent advancements in the YOLO family
The YOLO family of object detection models has seen significant advancements in recent years, with each new version introducing improvements in speed, accuracy, and robustness.
YOLO v6
YOLO v6 was released in October 2021 and includes several new features and fixes, including:
- Two new nano models, YOLOv5n and YOLOv5n6 that have ~75% fewer parameters than previous models and can run on mobile and CPUs.
- A new P5 and P6 backbone network that improves accuracy on small objects.
- Several bug fixes and performance optimizations
YOLO v7
YOLOv7 incorporates several new techniques, including:
- A new backbone network called PANet that improves feature aggregation and representation
- A new loss function called CIOU loss, which is more robust to object scale and aspect ratio variations
- A new anchor box mechanism called EfficientDet that reduces the number of anchor boxes needed without sacrificing accuracy
YOLO v8
YOLOv8 introduces many new features and improvements over previous versions, including:
- Anchor-free architecture: YOLOv8 uses an anchor-free architecture, which makes it easier to train the model on different datasets.
- Self-attention mechanism: YOLOv8 uses a self-attention mechanism in the head of the network, which helps to learn long-range dependencies between features better.
- Adaptive training: YOLOv8 uses adaptive training to optimize the learning rate and balance the loss function during training, leading to better model performance.
- Advanced data augmentation: YOLOv8 uses a number of advanced data augmentation techniques, such as MixUp and Mosaic, to improve the robustness of the model to different variations in the data.
Other object detection algorithms inspired by YOLO
The success and innovation of YOLO catalyzed a plethora of research in the realm of object detection. Many algorithms have taken inspiration from YOLO's design principles, attempting to replicate its success or address its limitations. Here's a look at some object detection algorithms that were influenced by or drew inspiration from YOLO:
- Single Shot MultiBox Detector (SSD): SSD is another popular single-pass object detection system, which, similar to YOLO, aims at predicting category scores and box offsets for a fixed set of default bounding boxes. While SSD's design differs in many ways, it shares YOLO's philosophy of performing detection in one forward pass of the network.
- CornerNet & CenterNet: Instead of predicting bounding boxes, these models detect objects by finding their corner or center points. While their approaches are distinct, the drive to simplify and streamline detection is reminiscent of YOLO's breakthroughs.
- RefineDet: This single-pass detector refines object locations in a cascaded manner. By combining the benefits of two-stage detectors (like Faster R-CNN) and single-pass detectors (like YOLO), it attempts to strike a balance between detection speed and accuracy.
- M2Det: This model focuses on multi-level feature extraction, drawing from the success of YOLO's multi-scale predictions. By extracting features at multiple scales, it aims to improve detection accuracy across differently-sized objects.
Key insights
The ongoing innovation will keep generating more demand for computer vision models, where YOLO will still hold its special place for several reasons: YOLO heavily relies on a unified detection mechanism that consolidates different object detection elements into a single neural network to perform computer vision tasks effectively. Thanks to YOLO, the models can be trained with a single neural network into an entire detection pipeline. It's not surprising that the algorithm found application in countless industries, eventually becoming the nexus for projects invested in object detection.
Is it the right solution for your project? SuperAnnotate's end-to-end solution will eliminate the headache of annotating, training, and automating your AI. Feel free to explore further opportunities in our marketplace.